In machine learning, it’s often a case of garbage in, garbage out. If you don’t have the right data it can be difficult to get good results with your model, no matter how fancy the algorithm you use. However, often the data you have to use is fixed: you can’t get better data without significant effort and cost. So having strategies for making better use of your data – feature engineering – can contribute significantly to the performance of your model. As Xavier Conort, winner of the Kaggle Flight Quest Challenge, says “The algorithms we used are very standard for Kagglers. […] We spent most of our efforts in feature engineering.”
Table of Contents
What is Feature Engineering?
Feature engineering is the process of transforming raw data into ‘features’ that better represent the underlying structure and patterns in the data, so that your predictive models can be more accurate when predicting unseen data. Feature engineering is a game of iteration and inspiration. Domain expertise comes in handy as finding what variables are missing, or redundant can make a big difference. For example in Marketing Mix Modeling, knowing what features to include can make all the difference to model accuracy and usefulness.
Better engineered features allow you to build less complex models that are faster to run, easier to understand, and less costly to maintain. With good features, you are closer to the underlying problem and more honest in your representation of the data you have available. After collecting and cleaning data, data scientists spend most of their time on feature engineering as investment in this area can really pay off. Automating this work can reap significant benefits over a long time frame, so knowing the common feature engineering strategies is a big advantage.
Feature creation falls into three main buckets. Feature creation involves creating new variables that will be helpful in our model. For example, formatting a datetime as a day of the week in order to create dummy variables in your model.
Transformations are when the data is modified in some way to form a different representation. A common example for marketing mix modeling is log transforming media spend to account for diminishing returns or saturation of a channel.
Finally, feature extraction is a method for reducing the number of features without distorting existing relationships or significant information, like a principle component analysis.
What is a Feature?
Your data is made up of observations, which usually are represented in tabular data as rows in a spreadsheet or database. Each of those observations has attributes, typically shown as columns, which tell us something meaningful or useful about the observation. These attributes are known as features when building a machine learning model.
Choosing the right features makes a considerable difference to the performance of your model. Choose too many features or select ones that aren’t meaningful to your model, and you won’t be sophisticated enough to be able to predict accurately. Include too many features and you may overfit to the data you have observed, so your model won’t be very accurate in the real world.
In marketing mix modeling a feature might be the amount you spent on a specific media channel, external environment variables like the average temperature, or a dummy variable for whether it was a holiday in that time period or not. Choosing whether to include specific features like seasonality makes a huge difference to your model, as each feature ‘controls for’ that effect and at least partially separates it in the equation. It pays to be intentional with your choices.
Feature Engineering Tactics
There are many methods for engineering features in common practice, but if you haven’t heard of them before you’re unlikely to know what to search for or when to use them. We’ve compiled a list of feature engineering approaches that we’ve used in our day to day data science work at Recast, where we build automated marketing mix modeling software. In this list, we’re covering everything we commonly use, and most anything else you need to learn will be similar or based on what you see listed here, so this is a great place to start.
Calculated Fields
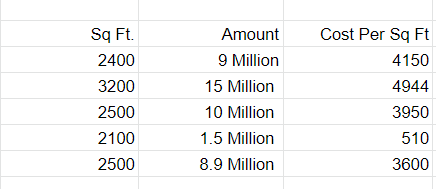
The simplest to understand example of feature engineering is to take existing features and use them to calculate a new feature, for example cost of a house divided by size in square feet to get cost per square foot. These calculated fields can reveal more useful patterns about the data and decrease the number of variables you need to include in your model.
Impute Values
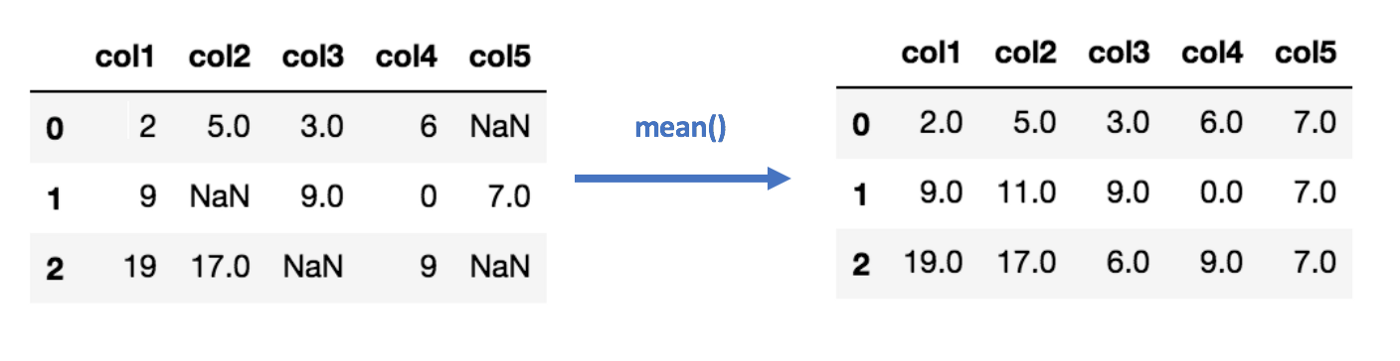
Imputing values is using a rule to ‘fill in’ missing values in a column, so that your feature can be used in a model. One strategy for doing this is by using the mean of the column for any missing values. This is necessary because most datasets aren’t perfectly clean and most algorithms won’t accept anything but perfectly clean data.
Outlier Removal
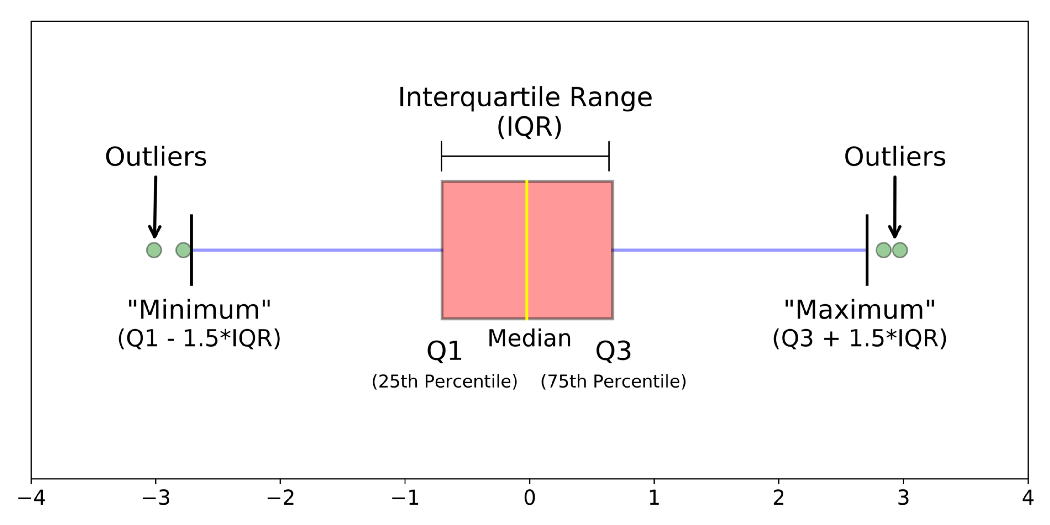
Often your data will have significant outliers that bias the results of your model. By detecting and removing them you can improve the results of your model. Commonly outliers are detected by calculating the interquartile range (the middle 50% of the data organized in order from minimum to maximum) and selecting outliers 1.5x below or above that level as outliers.
Discretization
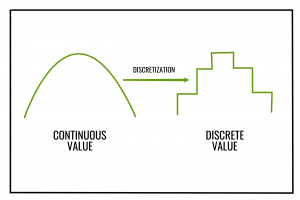
Sometimes a variable has too much variance. Meaning having a lot of granular data on something can actually provide too much noise for analysis. One technique for dealing with this is discretization, where you take a continuous variable and make it categorical. For example splitting average income into three buckets of ‘high’, ‘medium’ and ‘low’ might make an analysis more interpretable.
Binning
This concept is similar to discretization but can also be applied to integers or categorical variables. It is also called ‘grouping’ or ‘bucketing’. The goal is to decrease the number of properties so that the resulting model can be simpler, which helps to prevent overfitting of the data. Some variables work better with lower data fidelity, because leaving too many categories or properties could introduce unnecessary noise.
Reformat Datetimes
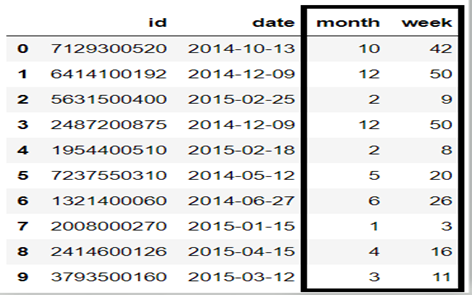
Dates are rarely stored in the format we need them. They are usually datetimes with too much information, or stored in a format specific to a country which can cause mistakes and confusion. It’s often better to extract out the month, week, or day as specific features for use in the model as separate factors.
Splitting
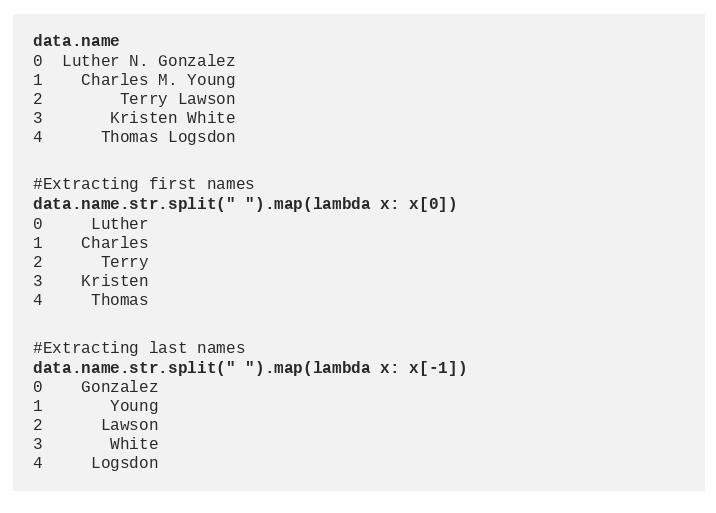
Often data is stored in a way that we need to extract something from a larger variable. The canonical example is splitting a ‘name’ column to get ‘first name’ and ‘last name’. This is often a first step before using another feature engineering technique to encode the variables.
One Hot Encoding
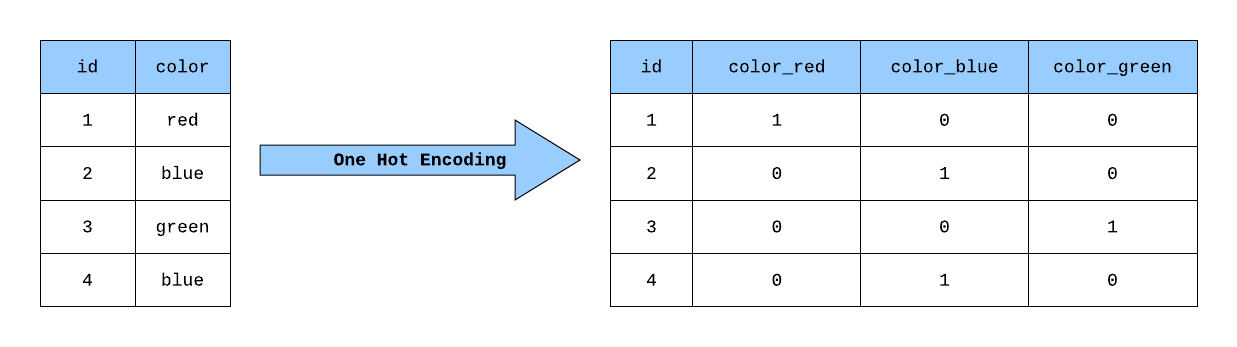
Most algorithms cannot handle categorical variables, so you need a technique for converting them into integers or floats. One common technique is one hot encoding, which takes each category and converts it into its own column as a dummy variable. Where it’s either a 1 if the observation is in that category, and a 0 otherwise. This is the reason why it’s common to want to decrease the number of categories, so you’re not left with too many features in your model.
Log / Exp Transform
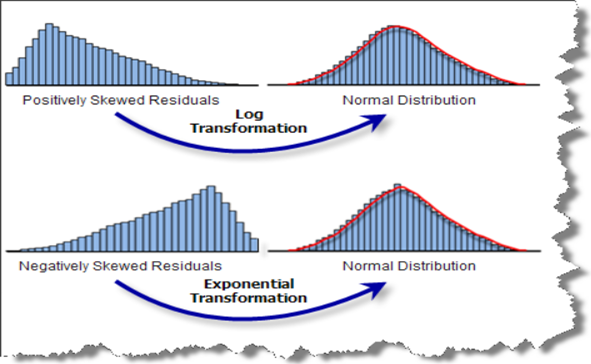
Many models or algorithms rely on the assumption of normally distributed data, for example linear regression does. This can represent a real problem if you have a variable that is skewed positively or negatively. By transforming the data using LOG or EXP functions you can map to a normally distributed variable to use in your model. This is common in marketing mix modeling when accounting for diminishing returns, or the impact of saturation of marketing channels at high spends.
Normalization
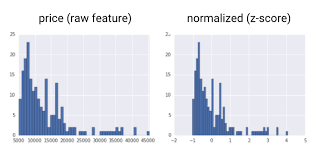
When building a model with multiple variables there can be a risk of some variables being treated differently purely because they are on a different scale. For example, if the price of a product and the amount spent on advertising a product are both included in a model, the advertising spend might be in the hundreds of thousands, far higher than price. To solve this it’s common to normalize or standardize the data so no information is lost about increases or decreases, but the scale is changed to avoid biasing the data. One technique is the Z-score, or number of standard deviations away from the mean, which maps the feature to having a mean of zero and standard deviation of 1, a requirement for some machine learning models.
Lagged Variables
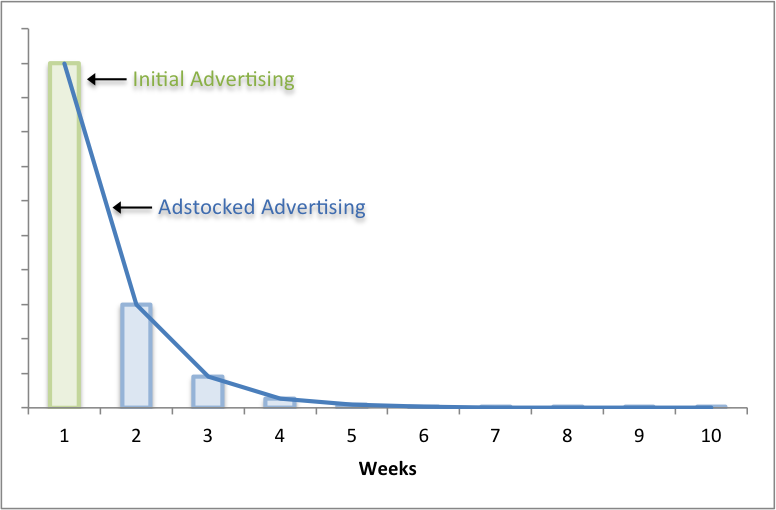
Most models assume independence between observations, but that might not always be true in time series models like we use for marketing mix modeling. For example advertising on TV today might influence purchase decisions for days or weeks to come. In this instance techniques like lags or adstocks transform a variable to account for influence over time.
FAQ
What is feature engineering?
Feature engineering is a tactic employed in data science aimed at improving model accuracy and quality by engineering features in datasets that did not previously exist. it usually involves applying domain knowledge to extract and create features from raw data.
What is an example of feature engineering?
Suppose a dataset of 3D objects contains height, length and depth, but not volume. Calculating volume from the existing data is simple and adds potentially useful data to the set.
Why is feature engineering important?
Feature engineering adds variables to a dataset by manipulating raw data that is already available. Essentially, it allows you to multiply the resources you already have and get more mileage out of your data.