Data intercepts and interacts with multiple business processes and tasks, which is why the phrase ‘data stack’ is useful. A data stack is a combination of data platforms and tools that work together to achieve a particular goal or set of outcomes.
In a modern business context, a modern data stack is generally used for tracking, collecting and routing customer data for analysis, persona building, segmentation, governance, customer journey orchestration and instrumentation in downstream tools, e.g. recommendations engines, marketing automation and personalisation. The stack covers everything from marketing to sales, compliance and product analysis.
A fully comprehensive modern data stack is a serious investment and will involve numerous tools and platforms ‘talking’ to each other in different ways. Once your modern data stack is fully set up, tuned, oiled and optimised for your business, it will likely pay dividends.
Given the vast constellation of data tools and products on offer today, this post will explore the ins and outs of modern business data stacks and what tools can be combined in what ways for business growth.
Table of Contents
The Main Aims of a Business Data Stack
A well-equipped data stack should achieve the following core aims:
Data ingestion: the extraction of data from databases or other sources using ELT data pipelines.
Data warehousing: the storage of ingested data, usually in a cloud-based data warehouse.
Data transformation: transforming the data into something that can be used in models and analysed.
Data analysis: segmentation, sales funnel visualisation and customer journey orchestration.
Data activation: setting clean, transformed data into motion by deploying it into recommendations engines or personalisation tools.
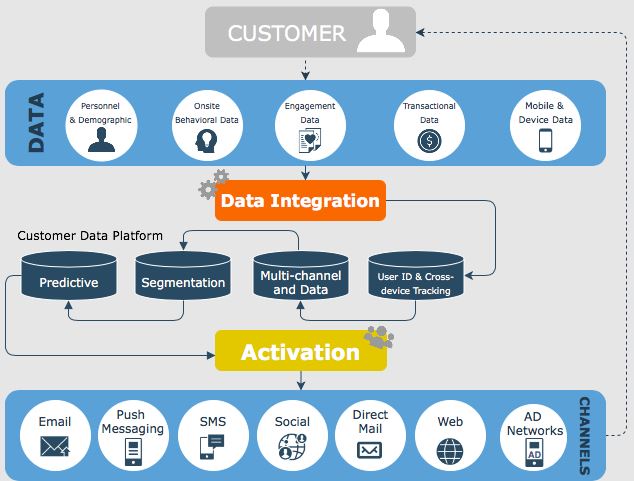
The key processes involved here are:
- Collecting event data from business touchpoints, e.g. websites and apps.
- Storing and routing that data.
- Analysing behavioural data, event data and other customer or user data to garner insights. Reports can also be created.
- Activating that data in tools to build customer experience models.
Let’s break those processes down alongside the tools you’ll likely need to accomplish the job.
What are the Benefits of a Modern Data Stack?
Building a modern data stack comprised of current-gen SaaS tools and cloud-native platforms represents a paradigm shift away from old on-premises solutions. Whilst large enterprises probably spent significant time and money investing in their own custom-built data solutions, SaaS platforms have proven that there’s really no other way to obtain world-class scalable data instrumentation. Much of these transformations have been supported by cloud-based data warehousing that enables analytics tasks to be performed at scale, and with the assistance of intelligent automation which has eroded the time hogged by writing transformation jobs and cleaning data manually.
The modern data stack allows businesses to tap into the tools they need to grow and thrive in a data-driven business world. One of the main benefits here is syncing multiple platforms, tools and departments into one unified stack. When once-disparate systems talk to each other fluidly, e.g. across the domains of marketing, customer services, sales, finances and products, it’s possible to reform teams to concentrate on actioning insights in opposed to connecting data manually across different touchpoints, not to mention saving the engineering time required to do that.
Collecting Event Data
The groundwork of event data are tracking tools, or data collection tools. These tend to fall under two main categories; the customer data platform (CDP) or customer data infrastructure (CDI). CDIs are focused more on the technical and routing side of customer data whereas CDPs are a ‘system of action’. There are a few ways to get event data into CDPs, CDIs and other tools for analysis and action, including webhooks, UTM parameters, APIs and IoT.
CDPs are focused more on the actionable side of customer data and contain tools for building audiences, personas and categories. Many CDPs are built on top of CDIs – there’s little point in overthinking the differences between the two as they’re generally synchronous and not necessarily mutually exclusive.
CDPs and CDIs can ingest data from third-party tools into their data warehouses using event-driven APIs, but third-party ELT tools ranging from Meltano to Xplenty, Stitch, Airbyte and Fivetran are adept at this task and provide numerous other benefits for ingesting complex data in CDPs.
Customer Data Platforms
CDPs do come with some of their own first-party data ingestion tools in the forms of SDKs, but their core functionality is identity resolution for the purposes of building and segmenting audiences and personas. CDPs house all customer data as ingested from any and all sources and then makes it available in a non-technical, transparent and easy-to-manipulate format. Once customer data has been shaped and manipulated, it can be synced to external tools and platforms.
Customer data platforms are like an intermediary service for customer data, or an interface through which customer data flows in and out. They’re designed to create the ‘single source of truth’ of customer data as ingested through multiple touchpoints.
To do this, the CDP uses identity resolution:
Deterministically: Via the matching of customer IDs across each system alongside common information, like names, DOBs and email addresses. Very reliable when the data is present and there’s high confidence of its accuracy in each system.
Probabilistically: Calculates the likelihoods of different data belonging to the same customer, or two identities being the same customer. Better when first-party data is limited.
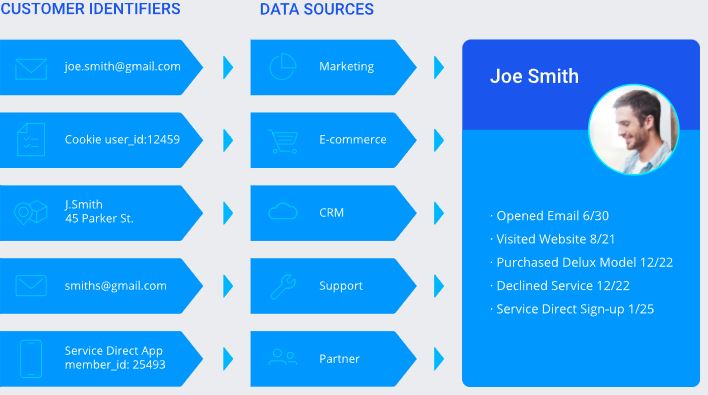
All CDPs provide these core features, and many will go on to provide a complex array of tools for business intelligence, customer analysis, journey orchestration and predictive or behavioural analysis. They’ve become sophisticated ‘all in one’ solutions for using customer data in various ways, often without particularly strong experience in data as a discipline.
The most popular CDPs available today:
Segment
Segment offers multiple customer data-oriented products including their core CDI solution as Segment Connections for collecting, unifying and using customer data. Segment Personas is angled more at customer experiences. Another add-on, Protocols, is a data governance tool.
mParticle
mParticle is a CDI at its core, augmentable with CDP identity resolution and audience building tools. Like Segment, mParticle also features a data governance add-on. mParticle is most popular in B2C spaces.
There are other CDPs offered by Exponea, Tealium and Lytics. Salesforce and Adobe have their own CDPs also. Segment and mParticle have the greatest market share.
Customer Data Infrastructure
Customer data infrastructure platforms are stripped down of their segmentation, personas and audience building capabilities. They bring data together using APIs and automation – sort of like a Zapier-type program but for data. As well as first-party data collection, CDIs are probably more technically oriented than CDPs and allow for more complex routing options.
Some CDIs include:
Avo
Avo is focused on product tracking and allows users to develop tracking plans with code for developers to insert to track event data.
Iteratively
Similar to Avo and designed for tracking. Both Avo and Iteratively integrate with Segment.
Segment Connections
Segment Connections is a CDI in essence, so can be used on its own without Segment’s CDP functionality in the form of Personas. The same applies to mParticle.
Rudderstack
A warehouse-first CDI and CDP solution and data pipeline for customer data. Rudderstack is open-source.
MetaRouter
MetaRouter is designed primarily for server-side data tracking. It runs off private cloud services or on-premises which suits it for enterprises that are subject to tight regulations or high-level privacy and governance.
Snowplow
Snowplow is targeted at behavioural data and offers a flexible platform for marketing and product analytics data. It’s highly scalable and works very well with exceptionally large datasets. Not solely a CDI.
Want to improve your data skills?
See the best data engineering & data science books
Warehousing Event Data
A data warehouse in this context is designed for the purpose of customer analytics and other customer data utilities.
Warehouses can store data collected from any and all customer data destinations.
CDPs do act as data warehouses to some extent whereas CDIs act more as pipelines, but CDPs are a system of action rather than a system of record and do not replace data warehouses. They’re different products and it’d be wise and astute to keep a copy of all customer data in a cloud data warehouse, most likely one of either Google BigQuery, AWS Redshift or Snowflake.
Having a system of record for raw data enables you to do much more with it than just customer and product analytics. Event data can be combined or transformed, cleaned or enriched prior to use (though CDPs and CDIs do make provisions for these tasks also).
Warehousing data early on in your business’s journey is sensible on many levels. Down the line, those many years worth of raw warehoused data can be used for everything from recommendations engines to predictive modelling.
Data warehouses from the aforementioned providers are inexpensive, easy to create and straightforward to operate and maintain.
In summary, it’s always wise to store customer data and event data inside of a data warehouse as well as using it or routing it with a CDP or CDI.
Analysing Event Data
Product analytics, behavioural analytics and customer analytics tools are used to analyse customer event data. Event data collected from customers is designed to help businesses study and understand the customer’s journey, interactions and friction points.
Websites and apps are the two main sources of customer event data in most conventional business contexts. Read up on how customer data and event data are intrinsically linked here.
Many of these tasks can be performed within a CDP without the need to route data to another downstream tool.
Analysing Event Data as a Funnel
Event data contains 3 core components:
- The action or the event that takes place
- The timestamp for the event
- The properties of the event properties
A simple example of event data would comprise these 3 actions in sequence – Add to Cart, Buy and Payment Completed.
Event data plays a key role in establishing what features users actually use, and how they navigate them. In product development, the features that users gravitate towards naturally can be prioritised and enhanced. Features that are neglected or avoided completely might need work, or can be removed.
Event data can also be used to improve UX and conversions, e.g. via A/B testing two landing pages with heatmaps. The user’s journey can be analysed and friction or pain points highlighted for optimisation or reworking.
Customer Data Analysis Tools
Whilst CDPs integrate native tools for identity resolution, segmentation, behavioural analytics and even orchestration, tailor-made tools are still commonly deployed to achieve specific business outcomes, e.g. product analytics.
Some tools you’ll want to compare against your needs include Heap, Mixpanel and Amplitude. Other options include Rakam, Indicative and PostHog. These can all be integrated with tracking solutions and CDPs like Segment and Rudderstack.
Each has its own strengths and limitations, e.g. PostHog and Heap are oriented towards codeless event tracking, or auto-capture. Rakam and Indicative are warehouse-centric and work well with data stored in popular data warehouses.
Before You Sync Data
When using different tools, use the same data where possible. So, if a business also uses a business intelligence tool as well as a product analytics tool, the same data should be fed into both.
It makes sense, then, to clean and model data prior to syncing it up to different tools, especially when you’re using more than one.
Activating Event Data
Data activation simply means actioning data, or transitioning data from a static entity that provides insight to a moving entity that provides action. When customer data is activated, it can be used in the funnel to engage, retain, acquire or otherwise help influence customer action.
Data analysed for insights need to be activated to put those insights into motion.
Customer data needs to be made available in downstream tools. Activation is typically angled at marketing, advertising, sales or customer service – these are the primary business departments that can benefit from personalised, timely data.
Data Activation Tools
There are a plethora of tools available for data activation – it ultimately depends on the end goal.
- CDIs are used to sync and upload data to downstream tools
- CDPs combine customer data for segmentation and syncing to downstream tools
- Destination integrations with product analytics tools or business intelligence tools allow you to sync customer and user data to downstream tools
- Reverse ETL syncs pre-modelled data from warehouses to downstream tools
CDIs
CDIs are extremely useful and flexible when it comes to customer data routing. CDIs support a huge variety of third-party tools for customer and user data syncing. CDIs are routing-orientated and work well when a business is automating a wide spectrum of customer data tools rather than looking for a more streamlined all-in-one solution.
CDPs
CDPs are the classic route to piping customer and user data downstream for activation. Some CDPs do feature activation tools natively, however, allowing customer data to be activated in marketing campaigns, etc, across multiple channels.
This has been known as ‘data orchestration’. A key example is Segment that integrates with SendGrid and Twilio for running personalised SMS and email campaigns using data and triggers setup and managed within Segment.
Reverse ETL
Reverse ETL is fairly new but pretty simple and involves using warehoused data – which is typically used for analytical purposes – for activation instead.
This is also called ‘operational analytics’ which refers quite literally to the process of making analytics data operate a more practical task via activation. Some tools here include Census, Hightouch and Omnata. Reverse ETL is generally pretty high-level and will certainly require the service of a professional data practitioner or other data specialists.
Native Integrations
Some tools, e.g. Heap and Amplitude, have developed their own native integrations. Amplitude Recommend allows for customer and user data activation from the same integrated platform.
These integrated solutions work very well for businesses that do not need the hassle of multiple routing and flexibility.
Summary: Modern Data Stack for Business Growth
This guide provides somewhat of a blueprint to map out what data services and products you might need to form your own data stack. Whilst most of the tools here are high-level, aimed at those who are already experienced and qualified in data, the barriers to access are coming down.
Another layer to the story is that many of these tools are becoming ‘self-service’, making them usable outside of specialist product, sales and marketing teams. The process of data democratisation is well underway and promises to provide more equitable and proactive access to data services across teams that are not already thoroughly immersed in this data landscape.
FAQ: Modern Data Stack
What is a data stack?
A data stack is a group of tools that work with data, usually in combination with each other. Some typical tools included in a data stack include data warehouses, ETL tools, business intelligence, product analysis and marketing automation tools. CDPs, CDIs, ETL, reverse ETL and data warehouses work together to create unified, automated business data systems that talk to each other using data ingested via multiple touchpoints, e.g. apps, websites, products, in-store systems, etc. Modern data stacks for businesses allow customer data to be unified, stored, transformed and deployed into everything from recommendations engines to marketing automation and personalisation.
What are customer data platforms?
You can read all about customer data platforms here. They act as an interface and database for customer data, creating a unified, combined ‘single customer view’ of customers using data ingested across all available business touchpoints. This unified customer view can then be analysed, segmented and implemented in the CDP natively or in downstream tools.
What are CDIs?
CDIs enable the cross-channel ingestion of customer data from multiple channels or touchpoints, routing it and syncing it to other tools for action and instrumentation. Many CDPs are built on top of CDIs – CDIs are the ‘plumbing’ that moves customer data around a stack.