

The simple, structured format of Twitter and its various posting functions makes it relatively easy to navigate and scrape.
Scraping Twitter can yield many insights into sentiments, opinions and social media trends and could helping building a programmatic SEO project. Analysing tweets, shares, likes, URLs and interests is a powerful way to derive insight into public conversations.
The Twitter API does allow users to read and write Twitter data. Using the Twitter API instead of scraping Twitter data ensures compliance with Twitter’s terms of service, but it’s not as efficient or flexible as using scraping services.
In fact, a recent study on Twitter scraping found exactly that – the authors concluded that scraping is more efficient and faster than using the API. The API also limits how many tweets you can scrape.
This is a guide to Twitter scraping – the content is intended for educational use only.
Table of Contents
Is Twitter Scraping Allowed?
It’s nearly impossible to determine this with any confidence. In effect, any data considered ‘open source’ can be mined legally, with some caveats. However, social media data can rarely be regarded as open source, which complicates the process of data mining.
Scraping publicly accessible data is generally legal and permitted so long as you obey the robots.txt file. Twitter’s terms forbid non-permitted web scraping; “scraping the Services without the prior consent of Twitter is expressly prohibited,” but breaking these terms is a civil matter, so it isn’t illegal.
Twitter data is scraped all the time and problems are rarely reported, if ever. This doesn’t form the basis of legal justification and merely highlights that the risk is low.
Scraping is a notoriously legal grey area – do your due diligence and research based on your motive and strategy for data mining and use. If you are concerned about legality or compliance then use the Twitter API.
If you intend on web scraping Twitter or any other site, check out the following guides:
- The Complete Guide to Residential, Backconnect and Rotating Proxies for Web Scraping
- Web Scraping With BeautifulSoup
- Is Web Scraping Legal?
- The Essential Guide To Web Scraping Tools
What About GDPR and Privacy Regulation?
GDPR is exceptionally complex, but it pertains mainly to processing and using data rather than scraping. That doesn’t mean that scraping is expressly permitted under GDPR. First and foremost, scraping personally identifiable information (PII) such as email addresses, phone numbers, names, addresses, passport numbers, dates of birth, etc, is far riskier and will involve GDPR.
For non-PII-data, things are generally a lot more open-ended. Are you going to get into trouble for scraping tweets for brand mentions or something similar? Probably not. Are you going to get into trouble for scraping emails from Twitter profiles and sending them unsolicited emails? Possibly.
If you want to scrape data for explicitly commercial purposes, or to use, sell or upload in some way, it’s wise to seek legal advice.
However, it’s worth highlighting that if your data mining operations result in damage to subjects or companies then you might be liable.
5 Ways To Use Twitter Data For Businesses
Understanding Customers
Twitter is a deep resource of customer insights. By surveying brand or product mentions, businesses can analyse the conversations surrounding their brands or products. Twitter today is widely used for customer service, and many people tag brands when they need assistance. This data can be mined and analysed for common issues or complaints. This also extends to positive customer experiences or discussions.
Influencer Marketing
Scraping Twitter data can help locate potential influencers. For example, industry-specific keywords and tags can reveal top posters. This provides opportunities to reach out to influencers via Twitter or another platform. Moreover, Twitter data helps you find what hashtags influencers are using so you can copy these to get noticed in similar hashtag streams.
Brand and Reputation Monitoring
Brand reputations are particularly important on Twitter. Negative stories have been proven to travel faster on Twitter than positive ones. Monitoring brand mentions and reputational comments allows businesses to quickly stub out any false negative stories, or respond to true negative stories promptly to mitigate reputational damage. Brand and product monitoring also help businesses improve services and products and provide on-hand advice to common issues.
Brand monitoring can also be used positively. For example, Ocean Spray created a successful viral campaign to deliver a truck full of their products to TikTok user 420 Dog Face, who filmed a video that featured their products.
Sentiment Analysis
Sentiment analysis targets the semantic meaning of tweets and content, i.e. their emotions. For example, if customers report positive sentiments around a brand or products using words such as ‘super, excellent, happy, content,’ etc, this is a positive sign. Conversely, if customers report negative sentiments such as ‘unhappy, annoyed, frustrated,’ etc, then this is a sign that the brand should intervene. Sentiments can help design customer service and even shape product and service improvements.
Competitor Monitoring
All of these techniques can be applied to competitors. It’s possible to analyse sentiments surrounding competitor products or services, or discover what competitors are doing well (or badly), so you can respond strategically. Monitoring competitors’ campaigns and Twitter strategies also reveal insights into how your brand can match or beat their winning tactics.
Twitter Data For Research
Twitter data also provides a rich account of thoughts, feelings, ideas, opinions and motives. Governments and public sector institutions mine Twitter data for political motives. Hashtags and comments can illuminate old, new and emerging sociopolitical trends.
In academic study, Twitter data is used for sociological, philosophical or political study and commentary. Journalists and the media mine Twitter data to explore trends. It’s also possible to compare sentiments surrounding current affairs and events to discover sites of dissidence or resistance. Key influencers can be identified for further research. Law enforcement mine Twitter data to uncover insights about propaganda or illicit activity. It’s worth acknowledging that Twitter likely sanctions such uses of Twitter data and that complex legalities apply.
Want to improve your data skills?
See the best data engineering & data science books
How To Mine or Scrape Twitter
One of the most popular tools used to scrape Twitter is ScrapeHero. ScrapeHero and other scraping services provide no-code services for scraping Twitter data without the Twitter API. Of course, just because you’re using a legitimate scraping service doesn’t mean that your scraping activity itself is legal or compliant, so make sure to do your own research and due diligence.
The following is an informational guide to scraping data from Twitter for compliant and legal uses only. Such information is intended only as educational advice.
You can typically scrape some of the following fields:
- Content
- Date
- Favorite
- Handle
- Hashtag
- Name
- Replies
- Retweets
- URL
Inputting URLs and Downloading Twitter Data
There are a few ways to provide input URLs to Twitter crawlers.
Firstly, you can get the target input URL from the Twitter Advanced Search function. Here, you’re able to filter based on people, dates, keywords, etc. You can toggle languages and set inclusion criteria for hashtags. It’s also possible to filter posts above or below a certain retweet threshold.
For example, if you input the keyword ‘Pfizer’ and set the field from 10/08/2014 to 10/08/2015, you will generate this URL:
You can also provide the target URL from an account:
https://twitter.com/pfizer_news?lang=en
Or a hashtag:
https://twitter.com/hashtag/Pfizer?src=hashtag_click&f=live
See ScrapeHero below:
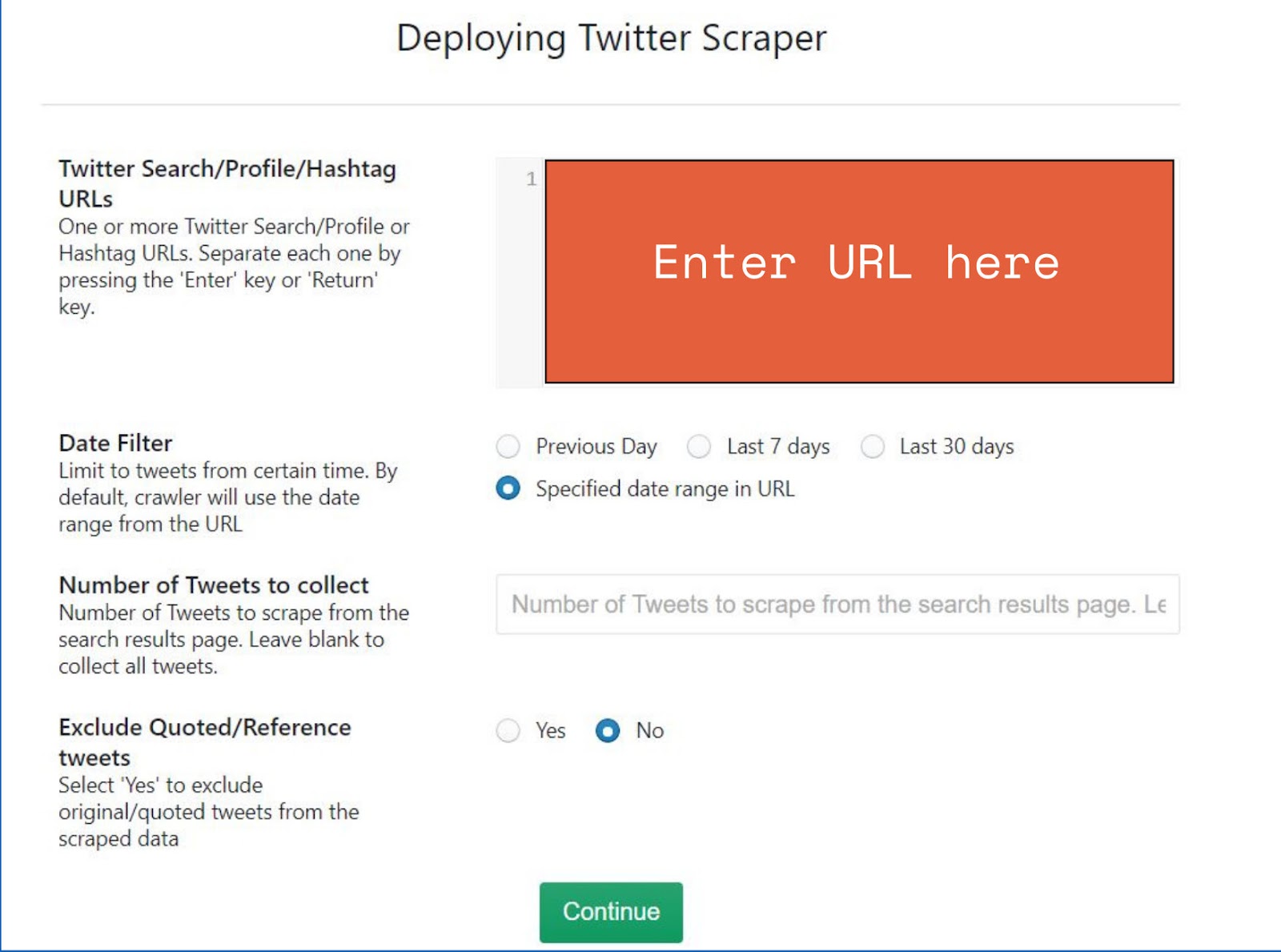
Once you click Continue, you will see the following window:

Once the Twitter Scraper finishes, you’ll be able to view your results and download the data. CSV, JSON and XML are typically available.
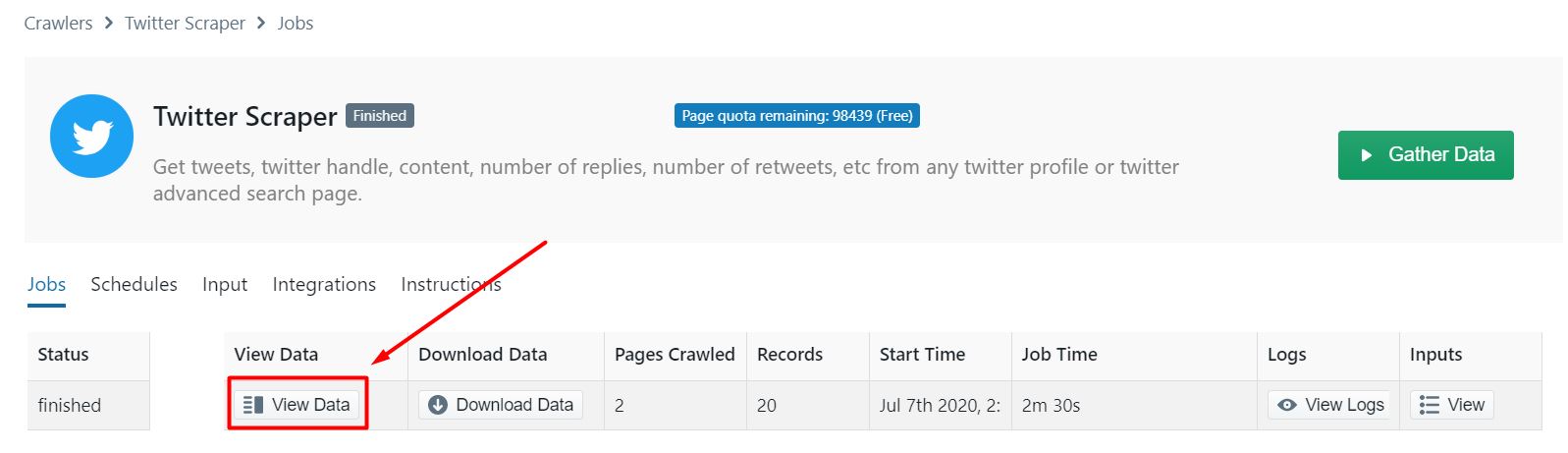
You’ll also be able to set up scheduled crawls for periodical scraping.
Processing Scraped Data
There are numerous ways to process scraped text data. For example, you might want to analyse a small sample by hand, but you might need to process the data using an NLP studio or manually using Python.
Here is a quick tutorial using Python and Notepad++. For sentiment analysis, you can find a list of positive and negative opinion words here. Care should be exercised when conducting sentiment analysis in this way, as the presence of an opinion word does not necessarily indicate positive or negative sentiment.
If you simply want to count the opinion words from either a positive or negative list, then you’ll need to clean your tweets to tokenize them for analysis.
with open (‘data.txt’) as f:
txt = f.read ()
txt = re.sub (‘[, \ . () “: ; !@#$%^&*\α] | \ ‘ s | \ ‘ ‘ , ‘ ‘ , txt)
word_list = txt.replace (‘ \n ‘, ‘ ‘) . replace (‘ ‘, ‘ ‘) . lower () . split (‘ ‘)
You’ll need to create dictionaries and parse your data to discover the total number of positive and negative words. Then, this data can be imported into a dashboard for visualisation.
Once you’ve tokenized your text, there are numerous ways to analyse your resulting data. Counting the number of positive and negative words is a quick and dirty way to discover sentiments. Ideally, it’d be better to use supervised or unsupervised models to extract deeper semantic meanings rather than simply adding up the words.
Manual analysis is a viable option for those who aren’t code-savvy, especially when working with small, detailed samples.
Summary: How to Scrape Twitter Data
Twitter is an exceptionally rich resource of human opinion, thoughts, feelings and ideas. In data mining, Twitter is useful for everything from deriving political and social opinions and trends to location brand and product mentions.
The legalities and regulations surrounding data mining are more fragile than ever, so make sure you do your due diligence based on your project and intentions. In addition, separate rules apply to the act of data processing than they do to mining itself.
FAQ
Is web scraping Twitter legal?
The legality of web scraping pertains mainly to the use of the data, rather than legality. There are situations where scraping personally identifiable information to use for certain reasons is a criminal and civil offence. Data mining is commonplace on the internet and most benign purposes for data mining are perfectly legal.
Is the Twitter API good?
Twitter allows access to the use of certain data via its API. The API is good for smaller queries but using other techniques for Twitter data mining are faster and more flexible.
What is Twitter data good for?
Twitter is excellent for many types of content analysis because Tweets are short, manageable and well-structured. The simplicity and regularity of Twitter content make analysis simple compared to other sources. Twitter data can be used for sentiment analysis, social insights, trends analysis, competitors, opinion gathering, reputational management, etc.

