
The bias-variance trade-off in machine learning (ML) is a foundational concept that affects a supervised model’s predictive performance and accuracy.
The training dataset and the algorithm(s) will work together to produce results, but ML models aren’t ‘black box’, and humans must understand the ensemble of interactions and tensions that affect their predictive capabilities.
The bias-variance trade-off helps describe prediction errors in supervised models.
The trade-off is also linked to the concepts of overfitting and underfitting. Together, these concepts help explain common issues in machine learning projects and illuminate methods to optimise the model.
Here, we’re focusing on the bias-variance trade-off specifically. Underfitting and overfitting will be introduced but are broken down into greater detail in this post.
Let’s go!
Table of Contents
An Overview of the Bias-Variance Trade-Off
Supervised machine learning involves training a model on (typically) human-labelled or annotated training data. Training datasets are designed to replicate, or mirror, the real-life data that the model will eventually be exposed to.
A well-trained, accurate model will be able to produce desirable predictions when exposed to real data as it did during training and testing.
Supervised algorithms learn to predict the mapping function between an input variable(s) and output variable(s). The mapping function is sometimes called the target function – the mapping function is the target of the learning process. The mapping function is predicted or approximated and is subject to the following errors:
- Bias Error
- Variance Error
- Irreducible Error
The irreducible error can be somewhat ruled out in this context. This is the error caused by unknown variables. These types of errors cannot be modelled out of the data and may be associated with how the training set was built and annotated.
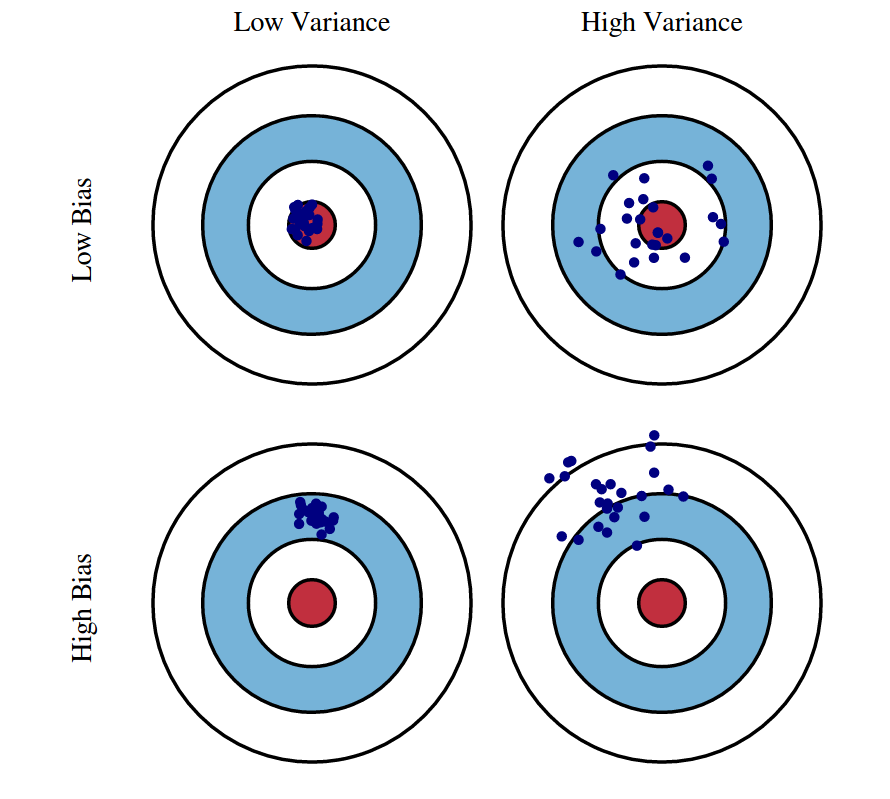
On the other hand, bias and variance errors fall within the remit of human control. We can visualise how errors increase with variance and bias, but also how the optimal model complexity does not necessarily intersect linearly with the two.

1: Bias Error
Bias error is technically defined as an error that arises between average model prediction and the ground truth. It results from incorrect assumptions made during the learning process. In a biased model, the model’s assumptions simplify the mapping of target functions, essentially ignoring other data in favour of making simple connections.
As a result, a highly biased model will fail to capture the true relationships between data. Simpler, linear algorithms are more likely to produce high bias.
- Low bias implies fewer assumptions about the target function.
- High bias implies more assumptions about the target function.
Three examples of low-bias machine learning algorithms are k-nearest neighbours, decision trees and support vector machines. In most situations, these algorithms don’t make simple assumptions and are usually more prone to variance error, as we’ll soon find out.
Three examples of high-bias machine learning algorithms are linear discriminant analysis, logistic regression and linear regression. These algorithms are simple and learn quickly but aren’t flexible when introduced to more complex data.
A high-bias model may:
- Fail to capture trends in the data
- Underfit
- Simplified and generalised
- High error rate depending on the data
2: Variance Error
Variance refers to what extent the predictions of target or mapping functions change when subject to different datasets. Since functions are only estimated, some variance is basically guaranteed in more complex models.
However, variance shouldn’t change too much from one representative dataset to another, as the model should be focused on discovering underlying trends that exist in all datasets. A high-variance model might be accurate during training, but then tends to overfit when exposed to test or real datasets. In other words, it doesn’t generalise well-enough – hence the bias-variance trade-off.
- Low variance algorithms make small changes to the target or mapping functions when changes to the training dataset are made.
- High variance algorithms make large changes to the target or mapping functions when changes to the training dataset are made.
Naturally, more complex non-linear algorithms are subject to higher variance unless efforts are made to reduce it (e.g. trimming or pruning decision trees).
Three examples of high-variance machine learning algorithms are k-nearest neighbours, decision trees and support vector machines. These algorithms are also typically subject to low bias.
Three examples of low-variance machine learning algorithms are linear discriminant analysis, logistic regression and linear regression. These models are potentially over-generalised or inflexible.
A high-variance model may:
- Capture trends in the noise of data
- Overfit
- Overly complex for the problem space
- High error rate depending on the data
Want to improve your data skills?
See the best data engineering & data science books
Bias-Variance Trade-Off
The bias-variance trade-off is inescapable – there is no avoiding the tension between the two:
- Increasing the bias will always decrease the variance.
- Increasing the variance will always decrease the bias.
In an ideal world, a model would accurately capture the regularities and trends of its training data, but generalise well to training sets or unseen data. Here, the model would have low bias and low variance.
However, this is usually not the case, and different algorithms tend to fall in one of the two camps, i.e. linear models risk high bias and low variance. In contrast, nonlinear models risk high variance and low bias. There are positives to glean from both bias and variance, so long as they’re balanced for the problem space.
Underfitting and Overfitting
Related to bias and variance are underfitting and overfitting.
Underfitting occurs when a model is unable to capture underlying trends in the data. For example, building a linear model using non-linear data may cause underfitting, or it may occur when training datasets are too small, or have a high ratio of noise to features. The ultimate result is poor performance. High bias, low variance models tend to underfit.
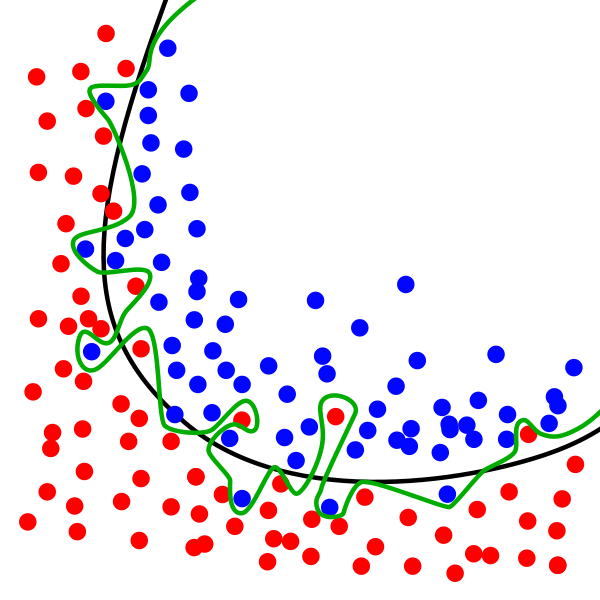
Overfitting occurs when a model over-learns and over-models the training dataset. In addition to underlying trends, the model might also overfit patterns introduced by noise or detail. This typically occurs in nonparametric and nonlinear models, and when there is a large number of features available (e.g. in an unpruned decision tree). Overfitting can be reduced by removing or regularising details and features, training with more data or changing some of the parameters of the model. High variance, low bias models tend to overfit. See the below diagram – the black line would better-encapsulate the underlying trend in the data shown (though would potentially risk being too generalised for some applications).
Influencing the Bias-Variance Trade-Off
The parametrisation and hyperparameter tuning and optimisation of machine learning affect the bias-variance trade-off.
Reducing data dimensionality and altering its features can reduce variance, but risk over-simplification. The inverse is to label or engineer more features and noise to decrease bias, thus risking high variance.
It might also be sensible to increase the complexity of the dataset to reduce bias and overfitting and increase the complexity of the model. Increasing training datasets is preferable when dealing with high bias, high variance models rather than low bias models that aren’t inherently sensitive to the training data (and thus, increasing the complexity of the training data would have little effect).
Otherwise, pursuing predictive accuracy might involve any number of changes to parameters and hyperparameters. For example:
- Linear models can be regularised to decrease variance, in turn increasing their bias.
- K-nearest neighbour (KNN) algorithms also have inherently low bias and high variance. However, the trade-off can be influenced by increasing the k value, therefore increasing the number of neighbours, increasing bias.
- A support vector machine (SVM) algorithm has inherently low bias and high variance. The trade-off can be influenced by increasing the C-parameter. This changes the number of permitted violations of the margin during training, thus increasing bias and decreasing variance.
- In an artificial neural network (ANN), variance typically increases and bias decreases as the number of hidden units increases.
- In decision trees, the depth and complexity of the tree determine the variance. The tree is pruned to decrease variance. Advanced deep decision trees can exhibit high variance as they have a high amount of flexibility to engineer hypotheses as they move through a large dataset.
Summary: Bias-Variance Trade-Off
There are three main takeaways here:
- Bias involves the assumptions the model makes to simplify the mapping of functions. A highly biased model may fail to capture trends and patterns in the data or neglect detail leading to underfitting.
- Variance refers to what extent the predictions of target or mapping functions change when subject to different datasets.
- The bias-variance trade-off is tension and interplay between both.
The bias-variance trade-off is foundational in supervised ML. While there will always be some level of trade-off or tension involved, it’s possible to influence the trade-off during model training and optimisation.
Changes can be made to the datasets and/or the model’s parameters to nudge the trade-off closer to either pole.
FAQ
What is bias in machine learning?
Bias sways a model for/against an idea without capturing the true trend. Thus, a biased model fails to capture the true relationships between data. Simpler, linear algorithms are more likely to produce higher bias out-of-the-box.
What is variance in machine learning?
Variance is the change to the model experienced when it’s subject to different datasets. A high-variance model will exhibit too-varied results when subject to different datasets, and therefore won’t be able to generalise well enough.
What is the bias-variance trade-off?
The bias-variance trade-off is the tension between bias and variance in ML models. Biased models fail to capture the true trend, resulting in underfitting, whereas low-bias high-variance models likely result in overfitting.

