
The term ‘modern data stack’ has become entrenched in tech circles as businesses and organisations around the world race to become data-driven.
Some 90% of business and analytics professionals identify data as a vital route to innovation, utilising their data to do everything from engaging new customers using data-driven marketing to selling more products using recommendation engines and personalised messaging.
Despite the evident benefits of data and the success of organisations that have invested in it, many of even the very largest businesses are lagging behind in their data strategies.
A 2019 report by NewVantage Partners, discussed by HBR, found that:
- 72% of participants stated they are yet to forge a data culture in their business or organisation
- 69% report that they have generally failed to create a data-driven organization
- 53% are still not treating data as a critical business asset
- 52% admit that they are not placing appropriate focus on data and analytics
Some of the barriers to success include not knowing what technologies to select – or simply not knowing where to start. A glance over the various tools and technologies that comprise the modern data stack, and how they’ve developed so rapidly over the last 10 to 20 years, reveals the complexities of choosing where to place their investment.
This article will analyse the state and progression of the modern data stack with an aim of decoding some of its past history and future direction.
Table of Contents
What is the Modern Data Stack?
The modern data stack for business growth involves a selection of tools that enable businesses and organisations to:
- Collect and track data from multiple touchpoints or sources
- Analyse and study data for data-driven insights
- Harness that data in tools for everything from customer segmentation and UX design to building recommendations engines, targeted marketing, product design and optimisation, etc
- Data is also being used for compliance and regulatory purposes, not to mention in cybersecurity and anti-fraud
Much of these processes and end goals require an eclectic set of SaaS tools, including:
- Data cloud warehouses, such as Redshift, Delta Lake, Snowflake and BigQuery
- Data ingestion services, such as Stitch and Fivetran
- ELT data tools such as dbt
- Business intelligence software, such as Mode and Looker
- Reverse ETL, such as Census
- Customer data platforms and customer data infrastructure such as Segment and mParticle
Many of these tools can be deployed in hours or days rather than months or years which was formerly the case with now-legacy data systems, but the vast quantity of tools (as the above are just a small selection) leads to somewhat of a crisis of choice that overwhelms businesses looking to become data-driven.
Whilst simpler free tools like Google Analytics work very well for small businesses and even SMBs, SMEs, enterprises and high-value startups often need to dig below the bare minimum and invest in a solid, future-proof, interconnected modern data stack.
Development and Progress in Data Technologies
The 1970s is when Edgar Codd published A Relational Model of Data for Large Shared Data Banks, probably the most influential technological publication of its time in terms of data and its related technologies at least. This began a process of RDBMS adoption. Major players from IBM to Oracle and Microsoft started rolling out databases and SQL was launched, making working with data much simpler. During this period, databases were obviously on-premises, predating the internet somewhat at the time.
This changed with the creation of the internet. The internet catalysed the Big Data movement where new solutions were developed to accommodate the vast quantities of data created via the internet. Some examples included Hadoop, MongoDB and Vertica which used SQL or NoSQL.
From here, data tools really rocketed in a period of rapid evolution, probably starting with Google’s BigQuery in 2010, quickly followed by Redshift and Snowflake, then leading to a whole host of cloud-based tools ranging from Looker to Mode, Segment to Stitch, Fivetran to dbt, Census to High Touch, etc.
A rough timeline for the development of many of these modern data technologies is as follows:
- Rapid development phase, from 2012 to 2016
- Businesses begin to deploy, from 2016 to 2020
- The future (for now), 2020 onwards
Crucially, many of these new tools allowed businesses to forgo cumbersome and monolithic on-premises data architecture to instead focus on picking and choosing the cloud-native tools required for their own growth. Businesses could see into their past and futures, utilising business intelligence to survey their direction and view KPIs in high-definition.
Many of these tools were fuelled by each other’s growth, quickly coming to the fore as an ensemble rather than individual entities. Redshift in 2012 was linked to a huge increase in funding for a vast selection of data startups. Conversely, those now-legacy systems that failed to make the grade quickly became enveloped by a tide of modern cloud-native tools.
Why Innovation is Still Required
The slowing rate of the development of data tools today is partly intrinsic to the development of any and all technologies – they are not able to escape the ‘S’ curve. The S curve postulates that technologies progress through a period of rapid growth before reaching saturation point.
In a data context, this is partly explained by the deployment stage which many businesses are currently still grinding through. Whilst developers build and market tools aimed at business growth, there is always a lag period in adoption – this lag period explains why those in the NewVantage survey are still lagging behind in their data strategies. It’s not about the tools themselves, as many can be set up in a matter of hours or days, but it’s about deriving value from the tools – this takes time and slows development.
Businesses and organisations are still busy working out how they can use their data, still busy reading signals to show that they’re heading in the right direction and deriving value from their (likely pricey) subscriptions.
Ultimately, this industry is still results-driven, and thus, data innovators must not rest on their laurels if their products fail to make an impact in the long game.
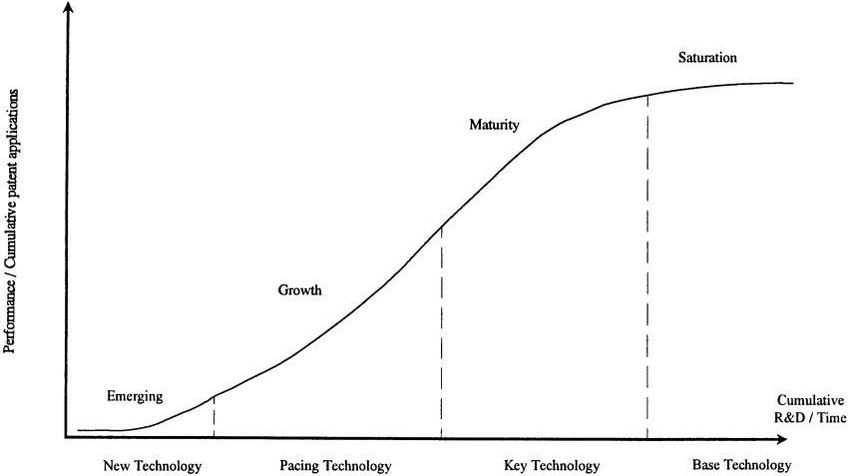
Whilst the S curve is a pervasive example of technological plateauing, it’s not inescapable. The next few years should see innovation in crucial areas that still bring about friction in businesses that are failing in their goals to become data-driven.
While many of the existing tools are fully equipped for modern data strategy when used properly, there is a dearth of features that help accommodate businesses that are not conventionally angled towards becoming data-driven.
The following capabilities will likely become the hallmark of future data stacks that can accommodate any and all businesses:
- Managed Options: The setup process is still as cumbersome now as it was 5 or so years ago. More SaaS providers are offering managed services that allow businesses to equip themselves with a useful stack with minimal input from internal teams. This will likely require collaboration across SaaS developers.
- Cloud Data Warehouse-Centric: This perhaps goes without saying; CDW data stacks should work off the shelf to enable swift communication between different tools.
- Streaming: Whilst the speed of modern data systems is nothing like it used to be, data streaming services are still more or less in their infancy, especially when dealing with complex data streams across industry verticals.
- Democratisation and Compliance: Data democratisation and compliance are more important now than ever; SaaS providers need to do more to make compliance easy to navigate.
- Elastic Scalability: Modern data stacks already scale well in most situations, but this can still be expanded.
- Automation and AI Augmentation: AI can both automate processes and augment processes that still require human action. Modern data tools will combine point-and-click functionality with AI augmentation and flexibility for dev teams.
The modern data stack also still suits agile startups and SMBs better than enterprises because of their limited data and fewer systems. Enterprises with legacy systems and complex data needs are the ones failing to make proper use of the current modern data stack unless they have virtually unlimited resources to draw from.
Want to improve your data skills?
See the best data engineering & data science books
Following on from the last heading, there are 5 key areas for innovation in the modern data stack:
- AI
- Data governance and democratisation
- Streaming
- Data sharing
- Closing the feedback loop
Artificial Intelligence (AI)
AI has long been considered the final frontier of software (and hardware) design, where creating life-like robots capable of human thought (and beyond) has been the crowning glory. AI lives everywhere; inside the internet, phones, IoT devices, cars, etc, etc. The pros and cons of AI have provided a fruitful discussion for everyone from Elon Musk and Stephen Hawking.
AI probably sits atop the ‘data science hierarchy of needs’, as below:
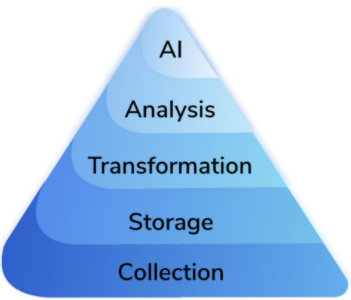
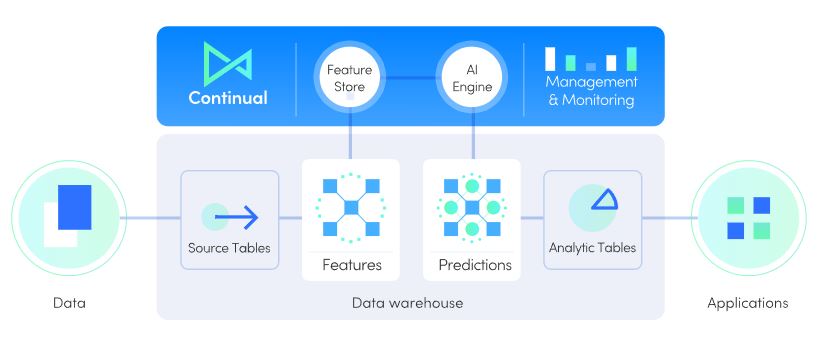
Therefore, the success of AI really relies on the tiers below it, including all manner of data engineering, data science, analytics and more. Data-first AI systems offered by those such as Continual offer a different means to utilise AI in the data pipeline, prioritising the automation of mundane and low-skill data tasks to unlock human resources elsewhere – which is one of AI’s primary benefits.
Continual touts itself as ‘the missing AI layer’ from the modern data stack, sitting on top of warehouses like Snowflake to assist businesses and organisations in creating sophisticated predictive models that continually stop learning from your data (hence the name Continual). These predictions are maintained in the layer for use downstream.
Data Sharing (Data-as-a-Service)
Some providers including Census and Hightouch provide data-as-a-service, enabling their customers to move data between cloud data warehouses and downstream applications without much intervention from internal data teams. This erases the need for bespoke custom integrations.
Data sharing services such as this also enable access to the same data across numerous companies, which also relates to the concept of ‘data trusts’ where data is pooled into a trust that is governed by an independent body in accordance with rules agreed amongst members.
Snowflake’s Data Marketplace provides another way for data-rich enterprises to provide access to others, an innovative platform for sharing data across sectors and industries. Expansion of these sorts of tools allows enterprises to extract value from their data beyond their own company or sector. Whilst the Snowflake Data Marketplace is excellent for those that share the platform, a more universal cross-platform system would be welcomed if vendors can navigate the associated competitional issues.
Data Governance and Democratisation
Two related concepts (both inside and outside of data), governance and democratisation respond to the internal and external regulatory, legal and also sociocultural ramifications of operating in a data-rich world where data has become somewhat of a manipulatable commodity.
Data governance also refers to how data-rich businesses and organisations govern their own data internally, e.g. via constant auditing, cataloguing, cleaning, etc. Data governance and democratisation tools enable businesses and organisations to ensure the robustness of their data and its access by various teams within the business, often via self-service tools. More on this in this blog about data democratisation.

Increased emphasis on data governance and democratisation will assist businesses in navigating their internal and external data responsibilities whilst seamlessly enhancing the visibility of data within the business itself, empowering teams with the data they need when they need it.
Streaming
Data streaming is perhaps the pinnacle of cloud data warehousing. Real-time is still in its infancy – it’s unfathomable to most larger businesses. Real-time is likely an inclement game-changer in data but at the moment, its uses are somewhat limited. But, that doesn’t mean that there is potential to exploit when robust data streaming becomes possible.
There are some early signs of real-time adoption amongst major providers; Snowflake’s Snowpipe is under constant development in the direction of real-time and Bigquery and Redshift are emphasising their materialized view functionality.
Real-time databases will likely arrive with a suite of real-time ingestion tools and downstream tools for making use of real-time data, whether that living, breathing customer dashboards and tools that respond with real-time data or on-demand business or operational intelligence which provides an immediate snapshot of a business at any given second.
Closing the Feedback Loop
Related to the above, the typical flow of data today runs from operational systems into the data stack where it’s picked up by humans. The modern data stack could additionally then feed feedback into the loop.
This could be used in the following examples:
- Customer service, where customer data could be piped directly into the customer service platform to assist in queries. Also possible with AI chatbots.
- Feed product click streams into products to create near-real-time personalised notifications and messages.
- Pipe product and customer information into CRMs to provide sales teams with more acute information on their clients and products.
In these cases, whilst real-time would be the pinnacle of a data stack looped completely across all platforms at both ingestion and operation ends, the latency of a few hours or so would be a great help for teams that can benefit from business or organisational information ingested and analysed a few hours ago.
Is The Future Bright For The Modern Data Stack?
That’s the million-dollar (or pound) question. Whilst data is at the frontier of modern business innovation, many businesses are still finding it difficult to know where to turn. Would more innovation help them, or make it worse? The jury is out on that one.
For now, working towards becoming data-driven in a determined yet considerate and granular fashion would work for anyone. Smaller businesses and SMEs should find it a lot easier to extract value from their data stack, whereas many enterprises founded pre-2010s have some backtracking to do to escape their legacy systems.
FAQ
What is the modern data stack?
The modern data stack for business growth consists of tools used to ingest, analyse and ultimately use data in a variety of tools and platforms that empower business growth. This might include numerous tools ranging from ELT pipelines to customer data platforms, business intelligence layers, reverse ETL, etc. These interlinked tools allow businesses to utilise data likely stored in a cloud database, piping it to various tools to build everything from advanced insights into a business and its customers and recommendation engines to optimised UX and product design.
What is the future of the modern data stack?
The modern data stack is highly-developed but has hit somewhat of a plateau in recent years, leaving behind the rapid growth of the Redshift years. Forthcoming additions will include the seamless integration of AI, development in data governance and data democratisation and an increase in managed services which make adoption easier.
How can I get started with data?
Business problems can often be formulated into questions where data is identifiable as the answer. If data can provide insights or solutions, then it’s about engineering a data stack to find and use that data. For example, if a business problem revolves around lost customers each month (aka. churn), then data might uncover insights about precisely when customers churn, who they are and what they do before they churn (e.g. stop using a product). This data can then be fed into personalised email marketing or notifications. Compare results post-strategy and see if there’s an improvement. Tweak as necessary. This is just one of many thousands of examples!

