So you’re looking to improve how you work with data, store data or enhance data quality?
Then you’ll likely spend some time data modelling!
Let’s get to it.
What Is Data Modelling?
Data modelling is the process used to structure how data is stored, as well as modelling relationships within the data.
The goal is to create a visual data map that accurately describes the data structure, how data will flow through the system whilst highlighting important data relationships. This can involve the data input itself, the data infrastructure and output, whether that’s predictive models, ML algorithms, AI or other products/services.
Database Data Modelling & Design Options
In modern software development there are three main ways of storing data:
- Relational Databases (Entity models): These are made from tables (tabular data) with solutions including PostgreSQL and MySQL.
- Object Databases (NoSQL): These are made up of key, value pairs and don’t have a strict schema, several solutions include Firebase, MongoDB and Amazon DynamoDB.
- Graph Databases (Tree): Graph databases are often seen within social networks such as Facebook, a graph database is composed of nodes and edges, several solutions include Neo4j, Dgraph and Grakn.ai.
Data Modelling In Relational Databases
Let’s imagine that we need to build an ordering system consisting of:
- Customers
- Orders
- Stores
The Store and Orders table could look like this:
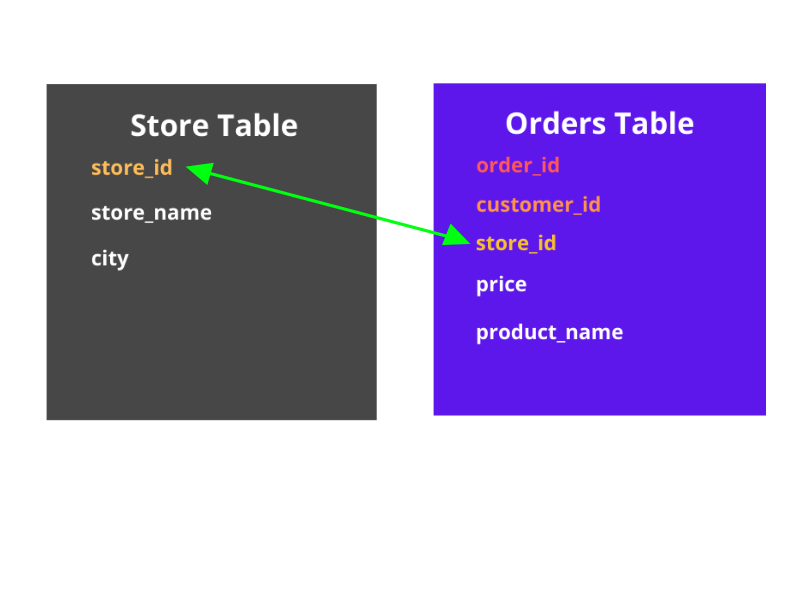
Notice the store_id field within the order table allows us to easily join (via a relationship) data between the store and orders table.
Customer table fields: customer_id, name, date_of_birth, location
Order table fields: order_id, customer_id, store_id, price, product_name,
Store table: store_id, store_name, city

Additionally, each order can be joined with the customers table via the customer_id field, providing the name, date_of_birth and location fields.
Larger, more complicated IT systems will require many more tables, each with their own set of relationships.

Data Modelling In NoSQL
Instead of tables and rows, we will create collections that hold documents. Let’s use the example from before, however we’ll modify a customer document to include a range of product ratings:
{
“customer_id”: 123,
“date_of_birth”: “13/09/1992”,
“Location”: "England”,
“Ratings”: {
“123”: 5,
“531”: 3
}
}
Notice how we can nest keys within our NoSQL database similar to that of JSON. This makes NoSQL databases very flexible structures as they are essentially schema-less.
Pro Tip:
You can still add primary keys in NoSQL like we did in the previous example. However if you have some nested data structures, you never don’t need to always create a flat structure.

- A products collection.
- An orders collection.
Data Modelling In Graph Databases

Graph databases consist of vertices (nodes) which are connected by edges (links). There are many different types of graphs such as an undirected network or a directed network.
Graph like structures are nested and are a useful medium for storing information within a network such as:
- Social networks: Facebook, Twitter, LinkedIn.
- Traffic networks: The UK motorway system or London’s underground subway system.
- Digital networks: The internet.
Modelling your data within a graph network makes more sense if:
- Your data is incredibly nested.
- There are many-to-many relationships within the data.
- You need to be able to analyse network effects.
Advantages & Disadvantages of Databases For Data Modelling
| Database Type | Pros | Cons |
| Relational Models | Provides well structured data. An easy to understand format for non-technical people. | The schema is fixed when the table is created, changes to the schema structure can be dangerous. Nested data must be flattened for it to be stored within a tabular form. |
| NoSQL Models | A flexible database for storing data due to being schema-less. Able to use joins whilst also allowing some of the data to remain nested. | You will need to spend additional time data modelling on the ideal number of collections. You might need to write complex, unique code to extract what you need from a NoSQL database. |
| Graph Models | Able to easily represent one-to-many or many-to-many relationships. You can apply a range of unique graph algorithms to analyse the data. | The data structure can be incredibly nested. Data can take longer to prepare and extract from a graph structure. There are only a few graph analysis libraries and there is less support for graph related computer science problems in comparison to SQL related problems. |
Want to improve your data skills?
See the best data engineering & data science books
When Is The Best Time Within A Project To Do Data Modelling?
Data models are best created early on within a good data project. A data engineer or data architect will decide based upon the needs of the application, what the ideal data structure and architecture will be.
What’s The Benefit Of Data Modelling?
- Easily Share IT System Concepts With Clients: Data modelling can be used to provide clients with an idea of what infrastructure needs to be built and why.
- Reduced Costs: By data modelling early on within a project, the data structures and relationships will likely be better. This will mean that any developers working on the progress will not likely need to make as many changes, thus reducing the development time and cost of the project.
- Stronger Data Architecture: Data modelling helps you to better understand the problem and types of relationships that you’ll use within a final solution. This is particularly useful for finding edge cases or unique scenarios that you would have likely missed if you’d have simply started coding. Stronger data architecture/structure can even help your application code to be more simple and less error-prone.
The 3 Main Stages of Data Modelling:
The 3 main stages to data modelling are:
- Conceptual.
- Logical.
- Physical.
Conceptual Data Models
Data modelling generally begins at a conceptual, abstractive stage where ideas are broken down into initial concepts. From there, the various broad components of the data system are created without any detail.
Concept data models are abstractive and their aim is to map out high-level components of a data project and to create a big picture of the system. They act as a storyboard or broad script – by painting with a broad brush, business requirements can be loosely linked to data systems.
The model components at this stage are composed of entities. The below entities include the time, which contains time data (e.g. time of day, week etc.), product, sales and the store. This sort of data system can link store data on sales to the products in stock and the time/amount they were sold at.
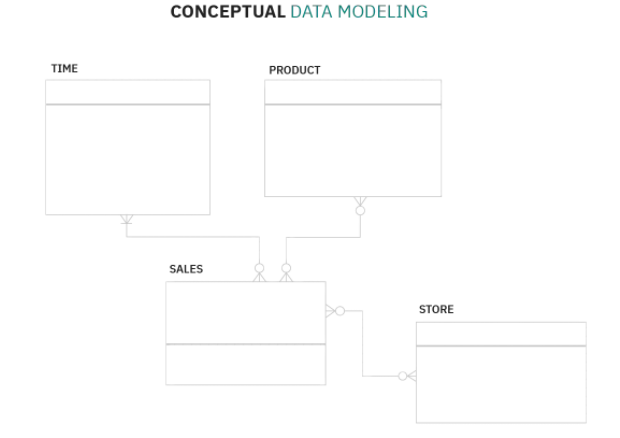
- Enterprise or business-wide coverage. Revolves around the customer, products and assets (in commercial settings, but many options are possible).
- Developed in conjunction with the business.
- Contains just entities using simple notation, as above.
- Links entities together in basic fashion.
- Doesn’t delve into DBMS, data infrastructure and technologies.
Want to improve your data skills?
See the best data engineering & data science books
Logical Data Models
Logical data models then add more detail about the entities and their relationships within the domain. Attributes are added to the model here. The modelling process here is still independent of technologies, but data types will be accurately listed alongside their definitions. In agile or DevOps practices, this stage may be omitted, skipping straight to the more comprehensive and final physical modelling stage.
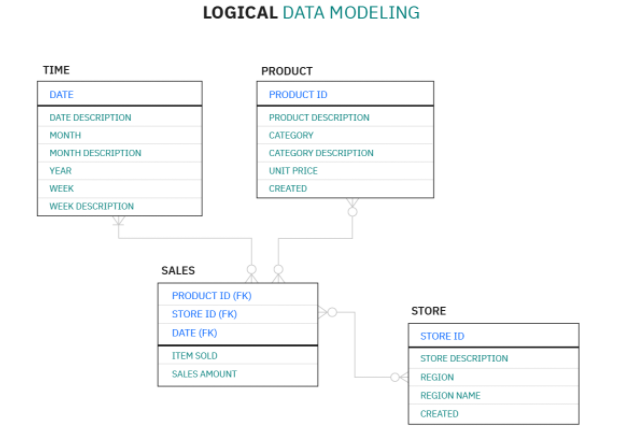
- Adds attributes to entities and establishes links.
- Defines the attributes.
- Add fields/schema and the data types (numeric, integer, string etc.) for each field.
- Specify primary keys.
- Assign nullability and optionality.
- Add metadata.
Physical Data Models
Physical data models glue the conceptual and logical models together with a technical schema.
They’ll show how and where data is stored, as well as the granular links that exist between data systems and their purpose. These include DBMS properties and are built specifically for the data technologies that will be used. Physical data models should be created alongside tables that illustrate the relationships between entities and attributes.
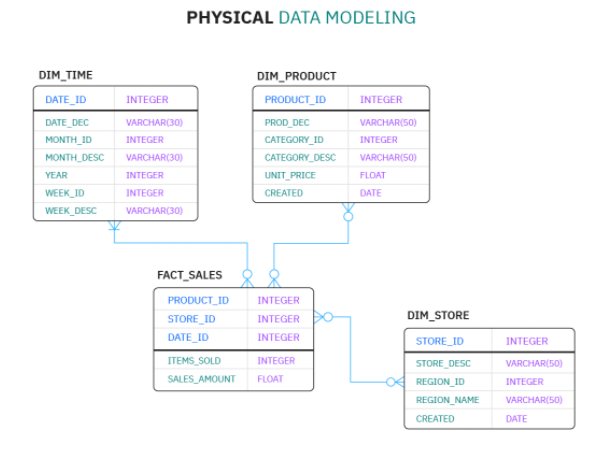
- Contains tables, cardinality and nullability relationships.
- Use foreign keys to establish relationships.
- Designed specifically for the data infrastructure that will be used.
- Data types, precisions and lengths assigned.
- Key project metadata.
A Data Modelling Checklist:
Below you’ll find a checklist of things to complete whilst you’re data modelling:
1. Identify Entities
Entities are the broad concepts or components, an entity could be a:
- Customer.
- Order/Transaction.
- Facebook Ads API Connector.
- Google Ads API Connector.
2. List Relationships
Relevant relationships between entities need to be identified. For example, a customer may be linked to an orders table based upon what products they previously bought.
Understanding the different relationships within your data will help you to create more robust and scalable solutions.
3. Explore Database Options
After identifying all of the entities and the relationships, you can now decide on the type of database(s) that would best suit your project.
Several things you might consider are:
- Are there one-many or many-many relationships?
- Does the querying need to be fast? (then you’d choose a SQL database such as PostgreSQL).
- Are you happy for the queries to be slower, then you might choose to use a serverless data warehouse such as Bigquery or Amazon Athena.
- Will some of your data be nested? If so, a noSQL database or graph database might be a good option.
4. Add Attributes To Each Entity
Each entity is distinct because it has different properties. These properties need to be dissected and assigned. Entities like customers will have attributes such as their name, age, gender, etc.
5. Assign Primary Keys
Primary keys allow for multiple entities to be easily mapped to each other. For example, a customer key can be linked to both their order history and address. This reduces database space by ensuring that data is never repeated in other tables.
6. Tune the Model
Data modelling is an iterative process, whilst working with your data architecture you will often come up with better ways that the data could be modelled and stored.
Data Modelling Frequently Answered Questions
What Is Data Modelling In SQL?
SQL data modelling involves writing .sql scripts to perfectly select, extract, group and join data so that it can be effectively analysed. This could involve cleaning the data from the raw database or combining multiple tables to create new metrics.
What Is Data Modelling In AI?
Data modelling in AI, involves structuring, cleaning and choosing a series of variables so that you can effectively perform machine learning. You might model relationships between variables such as cost * price. Additionally all of the data needs to be a numerical data type for a machine algorithm to process it.
What Does A Data Model Explain?
A data model helps you to explain how the data should be structured, stored and analysed. Depending upon your project a data model might represent a report, or it could be an entire IT system with visual diagrams.