
Overfitting and underfitting are two foundational concepts in supervised machine learning (ML).
These terms are directly related to the bias-variance trade-off, and they all intersect with a model’s ability to effectively generalise or accurately map inputs to outputs.
To train effective and accurate models, you’ll need to understand overfitting and underfitting, how you can recognise each and what you can do about it.
Let’s go!
Table of Contents
An Overview of Overfitting and Underfitting
Overfitting and underfitting apply to supervised machine learning. Supervised ML involves estimating or approximating a mapping function (often called a target function) that maps input variables to output variables.
Supervised models are trained on a dataset, which teaches them this mapping function. Ideally, a model should be able to find underlying trends in new data, as it does with the training data.
The learning process is inductive, meaning that the algorithm learns to generalise overall concepts or underlying trends from specific data points. By learning inductively from training, the algorithm should be able to map inputs to outputs when subject to real data with much of the same features.
The perfect model would generalise well without underfitting or overfitting and without featuring too much bias or variance. However, in reality, negotiating these poles is a tricky task, and there are usually modifications to make to the algorithm(s) and possibly the datasets too.
Underfitting Explained
The term underfitting is apt, as this is exactly what is going on. Underfitting means the model fails to model data and fails to generalise.
As we can see below, the model fails to generalise any sort of accurate trend from the given data points present.
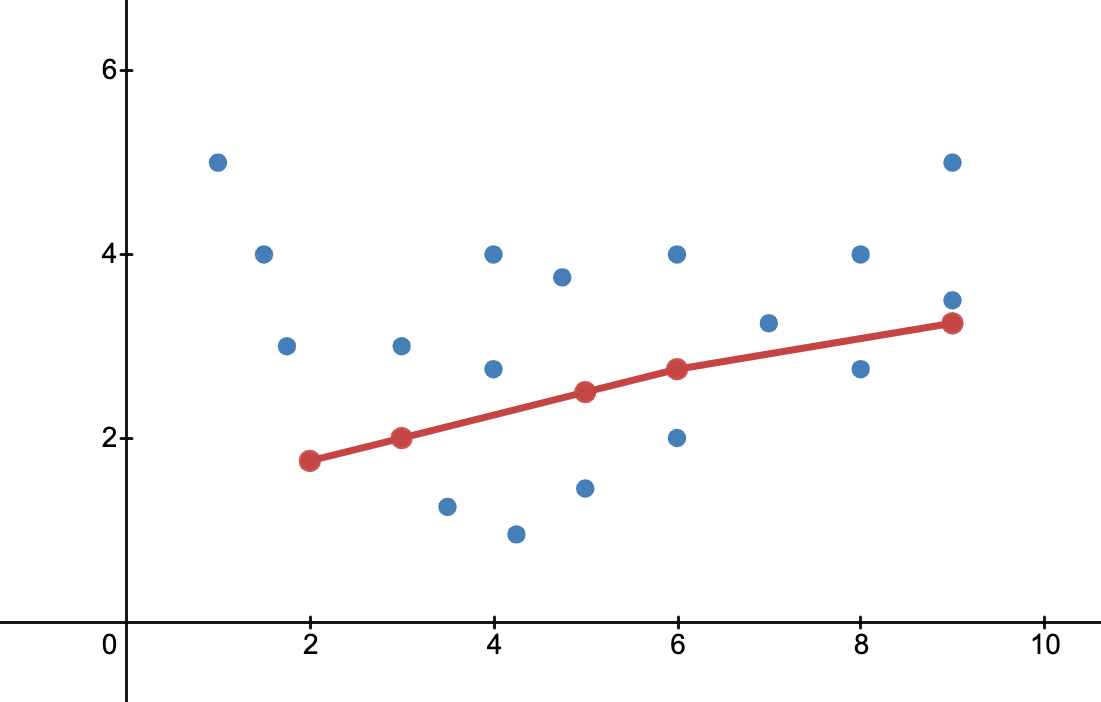
The model may not even capture a dominant or obvious trend, or the trends it does capture will be inaccurate. Underfitting shows itself in the training phase, and it should be relatively apparent that the model is failing to capture trends in the data.
What Causes Underfitting And How Do You Solve It?
Underfitting happens when there are too few features in the dataset, not enough noise and too much regularisation. The main issues may lie in the dataset itself (e.g. lack of noise and variance) or the training process (e.g. too short training duration). To avoid underfitting, the following solutions may apply:
- Decrease Regularisation: Regularisation aims to reduce variance by introducing penalties to input variables. There are many methods; dropout, L1 regularisation, Lasso, etc. Uniformity might be useful to an extent, but an over-regularised dataset will make it difficult for the algorithm to find underlying trends.
- Increase Training Duration: It might be tempting (or necessary) to stop training early to avoid overfitting, but this can result in underfitting.
- Feature Selection and Engineering: The features contained within a dataset vary hugely with the domain of ML (e.g. CV, NLP, etc) and the algorithms. Adding more features (or labelling more features in a relevant dataset, e.g. an image-based dataset), can add more variance to the model. Your data must effectively cover the problem space
Overfitting Explained
Overfitting is the inverse of underfitting. Here, the model is learning too well, and learns all the detail and noise from the training dataset. Consequently, the model will fail to generalise when exposed to real, unseen data. As we can see from the below example, the model is overfitting a rather jagged, over-specific trend to the data (the green line), whereas the black line better represents the overall trend.
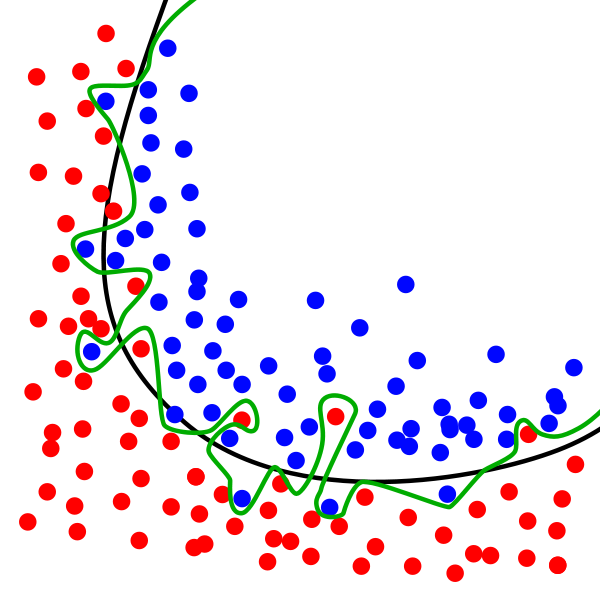
Overfitting is harder to detect than underfitting as it causes high accuracy during the training phase, even despite high variance.
This is more likely to occur with nonlinear models and algorithms that have high flexibility, but these models are often relatively straightforward to modify to reduce variance and lower overfitting. For example, decision trees, a type of nonparametric machine learning algorithm, can be pruned to iteratively remove detail as it learns, thus reducing variance and overfitting.
Want to improve your data skills?
See the best data engineering & data science books
What Causes Overfitting And How Do You Solve It?
Overfitting might occur when training algorithms on datasets that contain outliers, noise and other random fluctuations. This causes the model to overfit trends to the training dataset, which produces high accuracy during the training phase (90%+) and low accuracy during the test phase (can drop to as low as 25% or under). Like in underfitting, the model fails to establish the actual trend of the dataset.
There are various ways to accommodate for overfitting during the training and test phases, such as resampling and cross-validation. K-fold cross-validation is one of the more popular methods and can assess how accurate the model might be when shown to a new, real dataset, and involves iterative training and testing on subsets of training data.
Holding back validation data sets also ensures that you have untouched data, unseen to any algorithm, to objectively evaluate your model before deployment. Cross-validation and resampling are particularly useful when you don’t have enough data for training, testing, and validation data.
To avoid overfitting, or reduce overfitting in a model, the following solutions might apply:
- Using More Data: Using more data might provide the model with a wider window of opportunity to locate dominant underlying trends without overfitting. This really depends on what data your model has already learned from, and whether adding new data will help (e.g. by de-emphasising noise and fluctuations) or hinder (e.g. by reinforcing noise and fluctuations that already exist).
- Feature Selection and Engineering: The dataset might contain too much variance or be overly complex and feature-rich. Being more selective about what and what isn’t included in the training set can reduce overfitting. For example, labelling environmental features in an image dataset for a computer vision model (such as bushes, street rubbish, shadows and blurry features in a street scene) might introduce more complexity than an immature model can handle.
- Early Stopping: Pausing training before a model begins to learn from noise and other non-useful fluctuations can decrease overfitting. In practice, this often results in underfitting, and it’s necessary to find a balance by training for the optimal amount of time.
- Regularisation: It’s sometimes tricky to know what features to remove or re-engineer with increased simplicity in mind, which makes regularisation a great option for reducing overfitting. By introducing a penalty to certain input variables, regularisation techniques help reduce variance, therefore lowering overfitting.
- Ensemble Training: Ensembling essentially means using multiple algorithms which are then in some way combined or averaged to produce a singular, more-optimised model. Bagging is the most common type of ensemble training for tackling overfitting. Bagging decreases variance by creating additional data from training datasets, which are then used to train multiple models in parallel. These models are then summed or averaged into one model.
When Overfitting Doesn’t Apply
Deep neural networks and other highly advanced models are now trained to ‘exactly fit’ data, even when datasets are exceptionally large and complex. Here, the traditional bias-variance tradeoff tends to become a blurrier concept.
Research has shown that such models display a “double descent” curve, positing that increasing model capacity and complexity beyond interpolation results in improved performance. In other words, increasing model size makes performance worse and then better sometime after. This applies in model neural networking, e.g. CNNs, transformers and ResNets.
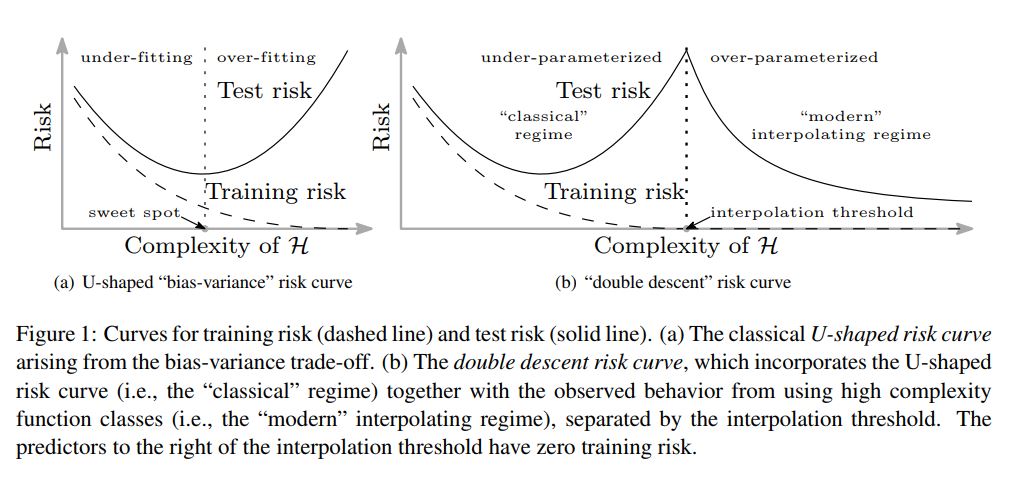
In time, we’re likely to see more examples of how modern ML projects distort the traditional definitions of overfitting and the bias-variance trade-off. But, for the vast majority of standard models and non-cutting-edge models, these concepts are still enormously important.
Summary: Overfitting and Underfitting in Machine Learning
There are two main takeaways here:
- Overfitting: The model exhibits good performance on the training data, but poor generalisation to other data.
- Underfitting: The model exhibits poor performance on the training data and also poor generalisation to other data.
Much of machine learning is about obtaining a happy medium. The training dataset is the first place to look for issues – engineering new features or otherwise modifying the dataset will affect the entire training process. Hyperparameter tuning and other optimisation methods can then shape the performance of a model to either increase or decrease bias or variance to improve overall predictive accuracy.
FAQ
What is overfitting?
Overfitting is when an ML model captures too much detail from the data, resulting in poor generalisation. It will exhibit good performance during training but poor performance during testing. Overfitting is one of the most common generic issues in ML.
What is underfitting?
Underfitting refers to when a model fails to fit any trend to the data. The model will exhibit poor performance during training.
How do you reduce overfitting?
Overfitting can be rectified via ‘early stopping’, regularisation, making changes to training data, and regularisation. Bad cases of overfitting might require more than one technique, or ensemble training.

