
Data science is taking a central role in modern business and when allied to effective well-planned business strategies, it has enormous potential to augment practically any business.
The scale of data in the modern world is quite staggering. According to Leftronic, 2.5 quintillion bytes of data are generated worldwide every single day. Businesses spent a whopping $187 billion on data projects in 2019 with 91.6% of businesses reporting increased investment in data science services.
As more businesses jump on the boat and ride the 21st-century data wave, there is enormous pressure on data scientists and engineers to tweak strategies and services to make data modelling, insights and predictive analysis sharper, stronger and more efficient.
In the wake of businesses prioritising data strategies en masse, it’s no wonder that many poorly planned data projects end up failing, often due to small issues that could have been easily avoided.
In this article, we’ll be discussing some of the most common problems in data science to prevent your data strategy from falling by the wayside.
Table of Contents
Planning Projects
Data science and the initial modelling process usually starts with a problem that needs to be solved. It doesn’t matter if we’re talking about business, sciences (e.g. meteorology, astronomy or chemistry), healthcare or economics.
Data science starts with a problem and data is identified as a possible means of obtaining a solution. Machine learning models can then be used to predict what will happen in the future and prescribe solutions to problems on an ongoing basis.
Problem 1: Not Understanding the Problem
The way you go about approaching the problem obviously depends on the goal or objective of the project. Some typical examples might be measuring ad campaigns and using predictive analysis to automatically target customers at time-sensitive intervals to maximise their potential, or A/B testing websites or landing pages to see which one captures more leads, customers or other metrics.
Some data problems are relatively straightforward but others are not and if you rush into choosing what data you want to collect and analyse first then you may reach a point where you realise swathes of data do not fit the problem, nor provide an adequate solution.
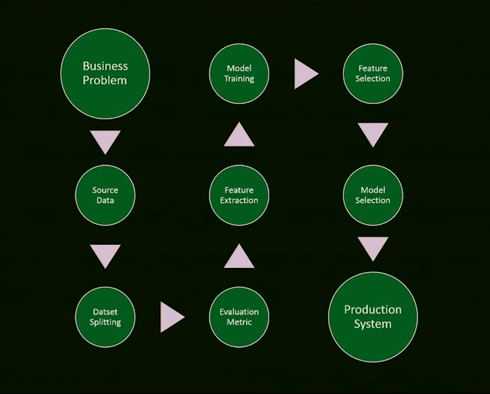
Solution 1: Define your Problem Correctly
Communication is key to establish the problem and philosophise possibilities without even starting to think about the data itself. Only then can you know what machine learning algorithms can be applied to work with your problem.
To adequately solve a problem, your data project should be able to:
- Identify, group and categorise data
- Analyse to discover patterns in the data
- Address the roles of outliers and anomalies
- Discover correlations and connections
- Predict outcomes
You may find that data science and modelling is simply not a good fit for your problem, or that more work is needed to identify a more specific element of the problem.
For example, you may have a problem with too many macro variables such as:
Are Londoners more likely to develop lung cancer from pollution?
You may think, well, I can find out who lives in London and compare this data to lung cancer diagnosis rates to discover the likelihood of Londoners developing lung cancer.
However, the term ‘Londoners’ introduces a unique problem in how this will have to be defined, does someone who moved to London a week ago count? What if they’ve lived there their entire life but only spend 50% of their time there?
Once you consider the problem in its fullest, you can see how you’ll have to adjust your data strategy and that you may need more data than you previously thought.
Solution 2: Organise Objectives within Paradigms
You can break down machine learning algorithms into three broad paradigms. Different aspects of your problem might fit into different paradigms and whilst it might feel elementary at first, reinstating your fundamental knowledge of ML is important before tackling a new project or task.
Unsupervised
Unsupervised algorithms use only input data for exploration, clustering and interpretation. Used for discovering and clustering sentiments on topics, groups of related phenomena (e.g. words in sentences when using natural language processing) or events that are probable to coincide.
Data collected via unsupervised models can then be fed into supervised models or deep neural networks.
Supervised
Supervised machine learning algorithms make predictions based on labelled input and output data. Supervised algorithms can be used for classification models, designed to classify and determine a label (e.g. a medical diagnosis) or regression, designed to predict continuous numerical patterns (e.g. temperature rises).
Reinforcement Learning
Reinforcement learning is designed to maximise a specific outcome from a variable system. A typical example here are machine learning algorithms that learn how to play logic games such as chess. RL algorithms need to balance exploration and exploitation to maximise learning from past experiences and refine future actions.
An Example: Refining Marketing Campaigns
A common problem may be to simply refine an advertising campaign for a product release.
You may choose to use unsupervised learning to explore and cluster sentiments around the new product, scraping data from social media and reviews. Sentiments can be clustered with what variation of an advert people are reacting to (e.g. an orange advert, or green advert).
Once sentiments are labelled alongside the adverts they correspond to, supervised models can be used to correlate sales data to discover if reactions to a product are linked with increased or decreased sales. This may help identify the strongest adverts that converted the most people.
For example, you may find that adverts involving the colour green evoked stronger positive sentiments. Reinforcement learning could then be used to automatically tweak the content of adverts to optimise their conversion rate for different groups of customers that responded strongly to different versions of that ad campaign.
The Data Engineering Stage
Problem 1: Issues with Infrastructure
With a well-defined problem and framework for using data to solve it, it’s time to focus on the data engineering process. Algorithms will never work properly without strong foundations in data. Rubbish in, rubbish out!
Data collection revolves around infrastructure, induction and storage (data lakes). It’s firstly important to understand what systems are already in place. Many businesses will have legacy systems using relational databases in SQL and may also have their own traditional models in place.
For example, a loans company may already use regression models to determine credit decisions.
Will you be able to tear out old models and migrate data infrastructure completely? Or will you have to navigate old infrastructure?
Solution 1: If it isn’t Broken, Optimise it
It is possible to implement new machine learning models alongside older data models and where this is time effective, it’s a valid compromise. Instead of replacing data infrastructure completely, you can consider building models to measure their effectiveness and then tweak them within their host infrastructure.
Instead of replacing models, you could build an ML model to test their accuracy and measure how effective or ineffective it is.
This saves you time in rebuilding data infrastructure where it isn’t necessary. Additionally, consider adding models to augment what is already there, e.g. ensemble models that help different elements of a business ‘talk’ to each other without strictly replacing them.
Problem 2: Data Collection
When you audit existing data infrastructure, you’ll discover what data already exists and what state it’s in. Of course, it’s always best to make the most out of what is there already and it’s likely that every business or organisation will have some data already.
Dirty Data
Dirty data includes all manner of mistakes but most commonly poor formatting and missing values. Typical examples are dates and times, which when manually recorded, can read in many different ways:
DD/MM/YYYY – 01/05/1993
DD/MM/YY – 01/05/93
MM/DD/YYYY – 05/01/1993
D/MM/YY – 1/05/93, etc, etc
There are hundreds, possibly thousands of variations when we factor in other mistakes!
Noisy Data
Noisy data is when errors or other anomalous and incorrect outliers muddle data. An example might be adding an extra character for someone’s age, turning 27 in 270. A weather system might be labelled as 28 degrees and also snowing by mistake, etc.
Missing or Sparse Data
Self-explanatory – when fields are left blank or some values are missing from a dataset, or when there is clearly not enough depth to the data.
Solution 1: Clean and Enhance the Data
Data cleaning is absolutely crucial and whilst building algorithms is the glamorous part of ML, data cleaning really is just that – cleaning – and it’s time-consuming and labour intensive.
Cleaning data revolves around restructuring and imputation, the process of replacing and changing missing or incorrect values.
Clustering and Binning – Data can be clustered to easily identify outliers and anomalies. This provides a simple means to remove incorrect data entries in ranges such as age, where 222 is easily distinguished from 22, for example.
Hotdecking and Colddecking – Educated guesses that allow you to input missing data based on other values.
Averaging, Median or Mean – Insert missing data as an average, median or mean of existing data.
Regression – Using a regression model to predict the value from other inputs.
Expectation Maximization – Determine the maximum likely expected value in a range.
Deletion – Delete the data altogether.
Solution 2: Induct More Data
You may find that existing datasets are just too poor to work with, but that data is readily inducted from other existing sources (e.g. another business department). You could then induct that data and perform cross-analysis to automatically build the strongest datasets you can from all pooled data.
Solution 3: Perform Feature Engineering
You can enrich sparse data by engineering new features from the existing data. For example, you may have data on when a customer last made a purchase. You can create a new feature from this data ‘did this customer make a purchase in the last 30 days?’
Engineering features allows you to enrich data to generate new creative insights.
Want to improve your data skills?
See the best data engineering & data science books
Problem 3: Non-Representative Datasets
Connected to the planning stage, you may discover that datasets are not representative of the problem in real-world terms. This is particularly relevant when working with unstructured data, e.g. material objects. A model working with this sort of data must learn from its features with the detail it’ll require in the real world.
For example, if we take the two below stop signs, an ML model using computer vision (e.g. in a self-driving car) would have to robustly learn the real-world features of a stop sign rather than learning from a cleanly edited image. If unstructured data is too perfect, this will cause the model to fail when it encounters its imperfect real-world form, e.g. a rusty stop sign with ivy growing over it.
,


Building Models
Once data has been collected and clustered using unsupervised ML algorithms, and then fed into a dashboard and visualised using software packages such as Seaborn, Matplotlib, Plotly, etc, it may be time to build predictive and prescriptive models trained on that data.
Problem 1: Overfitting and Leaky Data
Overfitting is an extremely common problem when training models and refers to when a model trains to training data too effectively, thus likely producing a very high performance measure right out-of-the-box (90%+). It will occur if a model learns noise in training data as concepts, which when unrepeated in new datasets, causes the model’s ability to generalise to fail.
Example: The model might be trained with only types of engineering CVs. The model might be trained to effectively discern between different classes of engineering experience and when tested with CVs purely related to engineering, it succeeds in predicting which is the strongest. However, when other it’s introduced to other classes of CV that also don’t include the same classes of engineering experience, the model fails.
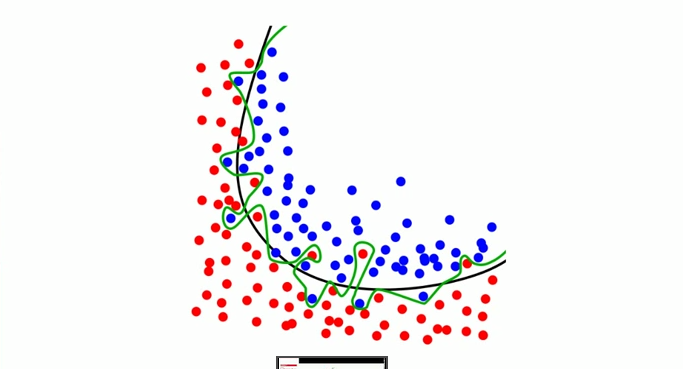
Data leakage is similar, but is when a model is trained using data that is unavailable afterdeployment, or when data is leaked between test and training datasets. The model works very well in a closed system but when deployed and opened up to real-world stimuli, it suffers from the lack of data it wasn’t exposed to during training and fails.
There are several main causes of data leakage ranging from using features to train models whose values change over time in unexpected ways to when the target and input data are in some way related.
Example: Similarly to the last example, we might build a model that learns from 10,000 CVs, all of which cover a wide spectrum of different characteristics. We might include some CVs with relatively unrelated experience in there, in architecture perhaps and not engineering.
An algorithm might be taught to write off these CVs completely in favour of those purely related to engineering, so when in real life, someone applies to an engineering job with both highly qualified architecture and engineering experience, the algorithm fails and renders the CV as having no chance vs candidates with just engineering experience. Thus is also an example of how bias forms in an ML algorithm.
Problem 2: Bias
Bias is one of the most fatal results from some of the above problems. Cyclical prejudices in ML models usually results from the data it is being trained with and this also relates to using data representative of the problem.
A prime example here are facial recognition technologies in driverless cars that found darker skin harder to recognise, an archetypal example of how bias originates from poor training data. Other ML algorithms such as Amazon’s recruitment algorithm were biased against women and ethnic groups owing to the fact the recruitment data it learnt from was also biased to these groups.
The role of potential bias in ML models should be foreseen before you start. Care should be exercised when any sort of data relating to gender, ethnicity, age or other human characteristics are being used. You’ll also need to remain aware of how a model might learn bias through proxy to other data that doesn’t strictly infer bias.
Solution 1: Cross-Analysis
Firstly, don’t be fooled by your model’s effectiveness. If you’re stuck in a ‘too good to be true’ situation when you run your first test then it probably is. Reflexivity and reflection is important here, you’ll want to reflect in target calculation and what variables you’ve utilised and inducted via feature engineering, examining whether these could bias your model.
In software engineering, there is a term called rubber duck debugging, where one will break down lines of code and explain them chronologically to an inanimate rubber duck, exposing any impasses or irrational decisions devoid of significant reason.
Cross Validation Techniques
Resampling can help provide a picture of what will happen when your model performs with unseen data. K-fold cross validation is a form of cross-validation where test data is divided into subsets folds, each of which is used at some point during testing, helping evaluation models iteratively.
Alternatively, you can use a validation dataset. This is an independent data set that hasn’t been exposed to your ML algorithms. Once trained, you can expose models to your validation dataset. Of course, if you have multiple samples of data, you can repeat this process multiple times.
Solution 2: Data Leakage
Data leakage is combated in similar ways and cross-validation will be your best weapon in examining the attributes that constitute unrealistic success of your model when exposed to test data and how this changes when exposed to real data.
Temporal Cutoffs
In iterative training, a model will improve until it starts to break down as overfitting and leakage surfaces. The idea is to identify the event at which error rates increase and then stop the model from passing that event.
Train Using More Data or Add Noise
Training using more data is a starting point when you know your data is not noisy and readily available, however caution must be exercised if there is any doubt whatsoever.
In both overfitting and data leakage, adding noise to training datasets expands it and can result in less generalisation error and regularisation as the model more robustly recognises signals amongst the added noise. A typical starting point is adding Gaussian Noise (white noise) to input variables.
Ensembling
Ensembling models essentially results in cross-validation and reductions in variance. Bagging involves homogeneous strong learning models trained in parallel that are then combined via some sort of averaging process. Boosting uses more weak learner models in sequence, each one relatively constrained, and then combines these into one strong learner. Bagging essentially starts with a complex model and reduces variance via ensembling whereas boosting combines weaker models to form a strong one.
Summary
No one said it would be easy!
Data science is fraught with problems and that’s what makes it so attractive to problem solvers. After all, that’s what science is all about.
Now machine learning intersects with data science in the modern era, the challenges are even more diverse. Luckily, as the challenges multiply, so do the solutions. Whilst it’s always tempting to delve into fighting fire with fire by using data techniques to solve data issues, you should always take time to use your biological brain to reflect on issues and think them through using a sort of rubber duck debugging technique.

